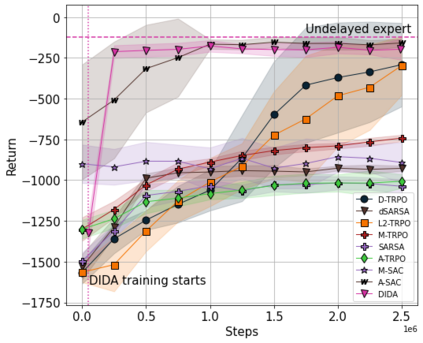
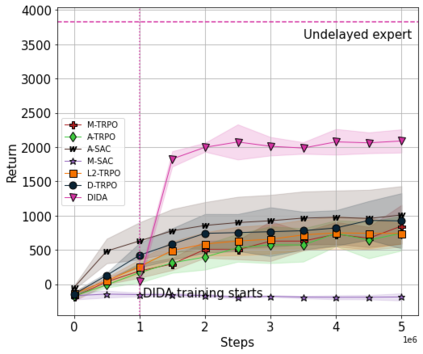
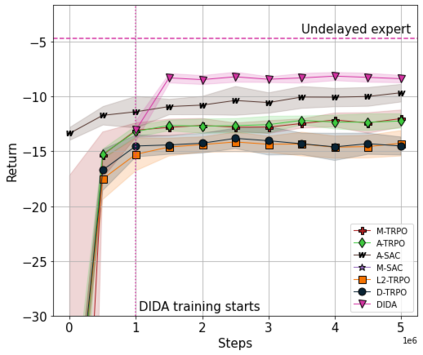
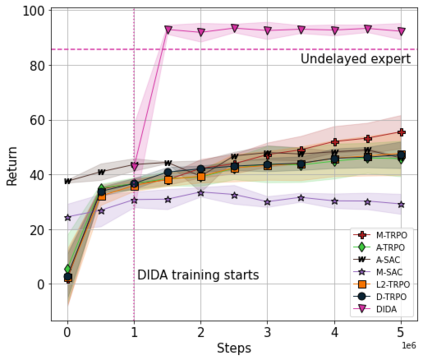
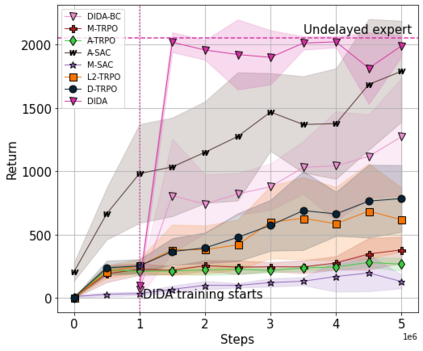
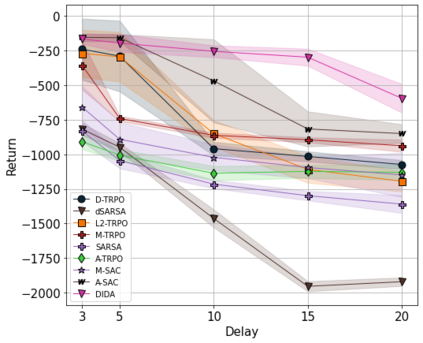
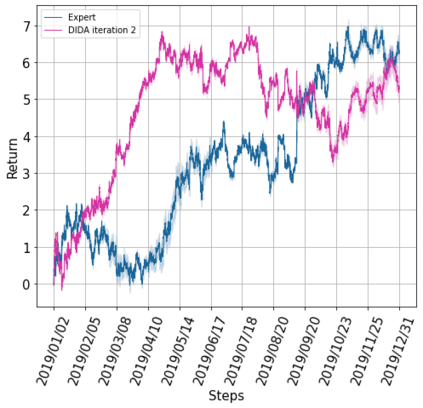
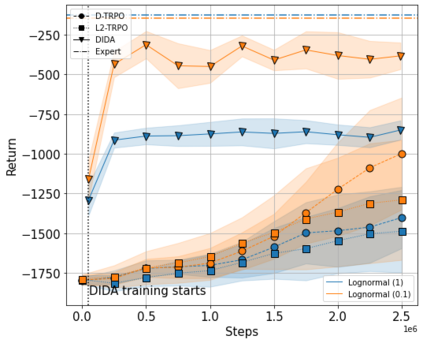
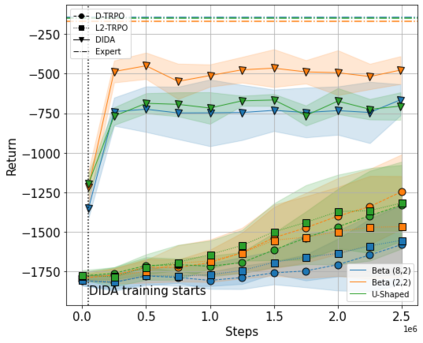
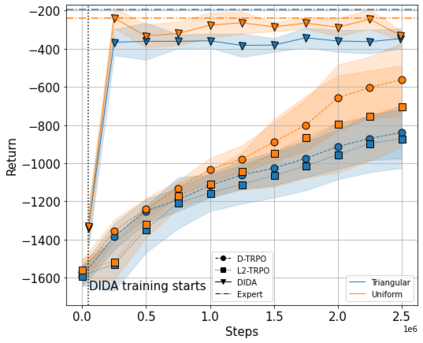
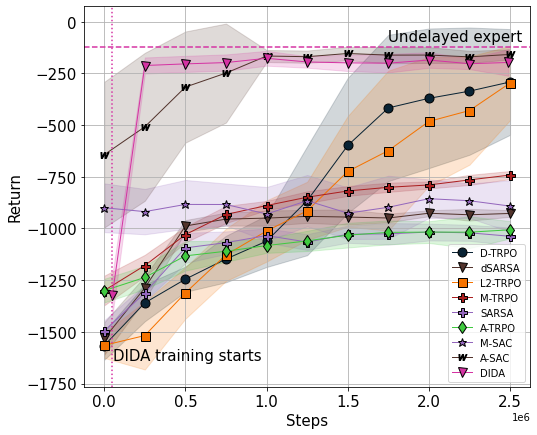
When the agent's observations or interactions are delayed, classic reinforcement learning tools usually fail. In this paper, we propose a simple yet new and efficient solution to this problem. We assume that, in the undelayed environment, an efficient policy is known or can be easily learned, but the task may suffer from delays in practice and we thus want to take them into account. We present a novel algorithm, Delayed Imitation with Dataset Aggregation (DIDA), which builds upon imitation learning methods to learn how to act in a delayed environment from undelayed demonstrations. We provide a theoretical analysis of the approach that will guide the practical design of DIDA. These results are also of general interest in the delayed reinforcement learning literature by providing bounds on the performance between delayed and undelayed tasks, under smoothness conditions. We show empirically that DIDA obtains high performances with a remarkable sample efficiency on a variety of tasks, including robotic locomotion, classic control, and trading.
翻译:当代理人的观察或互动被推迟, 经典强化学习工具通常会失败。 在本文中, 我们提出一个简单而新的高效的解决方案。 我们假设, 在未拖延的环境中, 高效的政策是已知的, 或者可以很容易地学到的, 但任务可能会在实践上受到延误, 因此我们想要考虑到这些。 我们提出了一个新奇的算法, “ 延迟与数据集聚合( DIDA ) ”, 以模拟学习方法为基础, 学习如何在未延迟的演示所延缓的环境中采取行动。 我们从理论上分析了将指导 DoDA 实际设计的方法。 这些结果对于延迟的强化学习文献也具有普遍的兴趣, 在平稳的条件下提供延迟和未拖延的任务之间的性能界限。 我们的经验显示, ANDA 在各种任务, 包括机器人传动、 经典控制和 交易上, 取得了出色的性能。