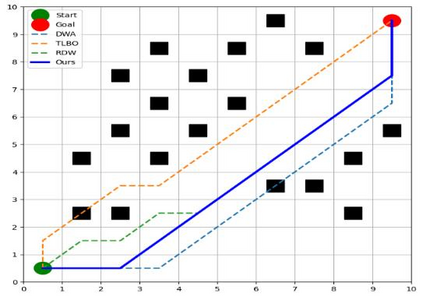
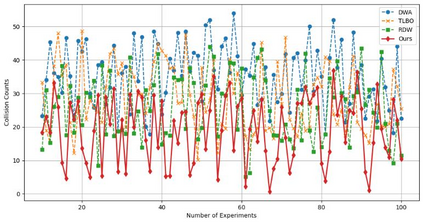
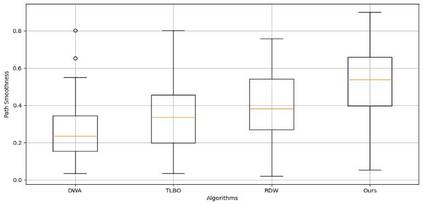
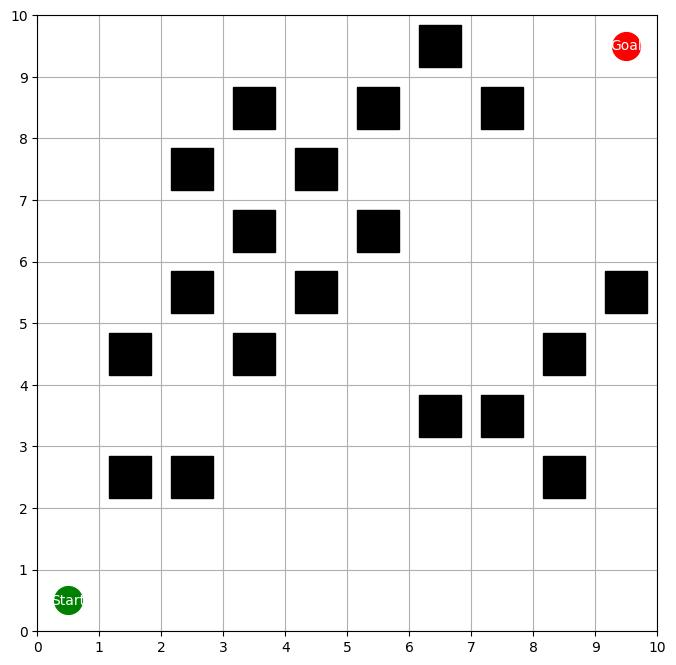
Reinforcement learning continuously optimizes decision-making based on real-time feedback reward signals through continuous interaction with the environment, demonstrating strong adaptive and self-learning capabilities. In recent years, it has become one of the key methods to achieve autonomous navigation of robots. In this work, an autonomous robot navigation method based on reinforcement learning is introduced. We use the Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process through the continuous interaction between the robot and the environment, and the reward signals with real-time feedback. By combining the Q-value function with the deep neural network, deep Q network can handle high-dimensional state space, so as to realize path planning in complex environments. Proximal policy optimization is a strategy gradient-based method, which enables robots to explore and utilize environmental information more efficiently by optimizing policy functions. These methods not only improve the robot's navigation ability in the unknown environment, but also enhance its adaptive and self-learning capabilities. Through multiple training and simulation experiments, we have verified the effectiveness and robustness of these models in various complex scenarios.
翻译:暂无翻译