成为VIP会员查看完整内容
VIP会员码认证
首页
主题
会员
服务
注册
·
登录
分词
关注
0
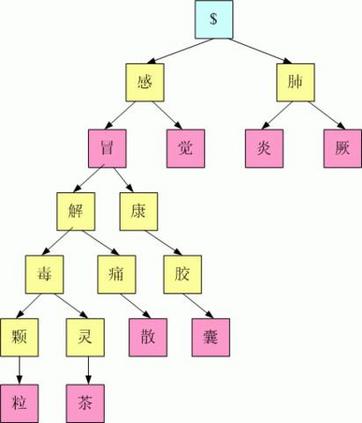
将一个汉字序列切分成一个一个单独的词
综合
百科
VIP
热门
动态
论文
精华
OccSTeP: Benchmarking 4D Occupancy Spatio-Temporal Persistence
Arxiv
0+阅读 · 12月17日
Panoramic Distortion-Aware Tokenization for Person Detection and Localization in Overhead Fisheye Images
Arxiv
0+阅读 · 11月25日
Idea-Gated Transformers: Enforcing Semantic Coherence via Differentiable Vocabulary Pruning
Arxiv
0+阅读 · 12月3日
Idea-Gated Transformers: Enforcing Semantic Coherence via Differentiable Vocabulary Pruning
Arxiv
0+阅读 · 12月11日
IndicSuperTokenizer: An Optimized Tokenizer for Indic Multilingual LLMs
Arxiv
0+阅读 · 11月5日
AtomDisc: An Atom-level Tokenizer that Boosts Molecular LLMs and Reveals Structure--Property Associations
Arxiv
0+阅读 · 11月28日
Information Capacity: Evaluating the Efficiency of Large Language Models via Text Compression
Arxiv
0+阅读 · 11月13日
ALTo: Adaptive-Length Tokenizer for Autoregressive Mask Generation
Arxiv
0+阅读 · 11月5日
DINO-Tok: Adapting DINO for Visual Tokenizers
Arxiv
0+阅读 · 11月25日
Comprehensive Evaluation on Lexical Normalization: Boundary-Aware Approaches for Unsegmented Languages
Arxiv
0+阅读 · 12月1日
Exploiting Vocabulary Frequency Imbalance in Language Model Pre-training
Arxiv
0+阅读 · 11月28日
Morphologically-Informed Tokenizers for Languages with Non-Concatenative Morphology: A case study of Yoloxóchtil Mixtec ASR
Arxiv
0+阅读 · 12月5日
Differentiable Hierarchical Visual Tokenization
Arxiv
0+阅读 · 11月4日
LoPT: Lossless Parallel Tokenization Acceleration for Long Context Inference of Large Language Model
Arxiv
0+阅读 · 11月7日
Which Pieces Does Unigram Tokenization Really Need?
Arxiv
0+阅读 · 12月14日
参考链接
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top