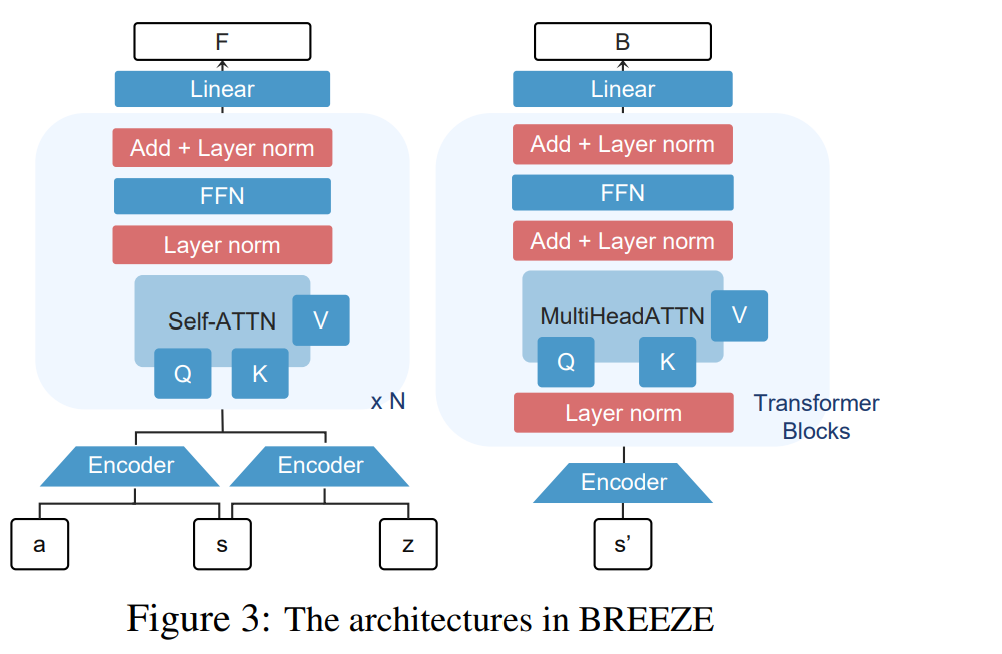
零样本强化学习(Zero-shot Reinforcement Learning, RL)的最新发展,为学习能够在零样本条件下适应任意新任务的预训练通用策略(pre-trained generalist policies)开辟了新的方向。尽管近年来流行的前向-后向表征(Forward-Backward, FB)及相关方法在零样本强化学习中展现出良好潜力,但我们在实证研究中发现,这类方法的建模表达能力不足,并且在离线学习过程中,由分布外(Out-of-Distribution, OOD)动作导致的外推误差会引起表征偏差,从而导致次优性能。 为了解决这些问题,我们提出了BREEZE(Behavior-REgularizEd Zero-shot RL with Expressivity enhancement),一种改进的基于FB框架的算法体系。BREEZE能够同时提升学习稳定性、策略提取能力以及表征学习质量。具体而言,BREEZE在零样本强化学习的策略学习中引入了行为正则化(behavioral regularization),将策略优化过程转化为一种稳定的样本内(in-sample)学习范式。此外,BREEZE通过任务条件扩散模型(task-conditioned diffusion model)进行策略提取,使其能够在零样本强化学习场景中生成高质量且多模态的动作分布。与此同时,BREEZE在表征建模中采用了基于注意力机制的高表达力架构(expressive attention-based architectures),以捕获环境动态之间的复杂关系。 在 ExORL 与 D4RL Kitchen 等基准数据集上的大量实验表明,BREEZE在性能上达到或接近当前最优,同时在鲁棒性方面显著优于以往的离线零样本强化学习方法。 官方实现已开源于:https://github.com/Whiterrrrr/BREEZE。