科学文献与在线信息量的指数级增长,使得从文本数据中高效抽取知识的方法变得愈发重要。自然语言处理(Natural Language Processing, NLP)在应对这一挑战中发挥着关键作用,尤其是在文本分类任务中。尽管大型语言模型(Large Language Models, LLMs)在NLP领域取得了卓越成果,但在**特定领域语境(domain-specific contexts)**下,其性能仍可能受到影响,原因包括专业词汇的复杂性、独特的语法结构以及数据分布的不平衡性。
在本系统性文献综述(Systematic Literature Review, SLR)中,我们重点研究了预训练语言模型(Pre-trained Language Models, PLMs)在领域特定文本分类中的应用。本综述系统分析了2018年至2024年1月间发表的41篇相关文献,遵循系统综述与荟萃分析首选报告规范(PRISMA, Preferred Reporting Items for Systematic Reviews and Meta-Analyses)的标准进行。研究方法采用了严格的纳入标准与多阶段筛选流程,并借助AI辅助工具完成文献选择与分析。
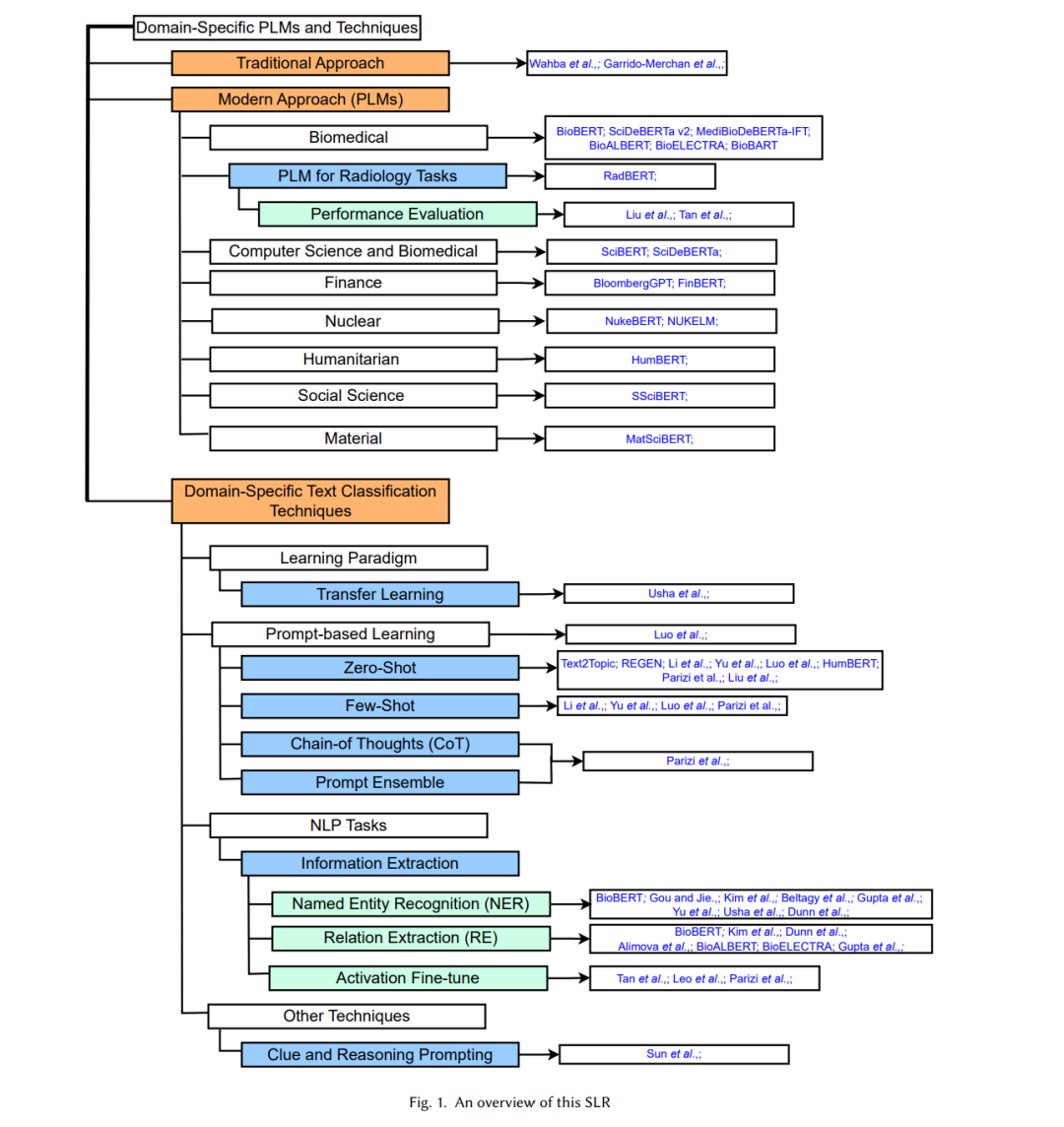
我们回顾了文本分类技术的发展历程,对比了传统方法与现代方法的差异,重点关注基于Transformer的模型,并探讨了在领域特定文本分类中使用LLMs所面临的挑战与关键考量。此外,我们根据不同类型的PLM对现有研究进行了分类,并提出了该领域的技术分类体系(taxonomy)。
为了验证综述中的分析结果,我们进一步进行了BERT、SciBERT与BioBERT在生物医学句子分类任务上的比较实验。最后,我们系统比较了不同领域中LLMs在文本分类任务上的性能表现,并探讨了PLMs在领域特定文本分类方面的最新进展,提出了未来研究方向与当前面临的局限,为这一快速发展的研究领域提供了深度洞察。
1 引言
近年来,各学科领域的科学文献发表量以及在线信息规模都呈现出爆炸式增长 [2, 6, 17, 31, 37]。这种指数级的增长进一步加剧了从文本语境中高效提取知识的需求。自然语言处理(Natural Language Processing, NLP) 是应对这一挑战的重要技术,尤其在文本分类(text classification)任务中发挥着关键作用 [6, 9, 24]。文本分类在诸多NLP任务中具有核心地位,包括情感分析(sentiment analysis) [3, 5, 28]、主题建模(topic modeling) [26, 32]、信息检索(information retrieval)以及自然语言推理(Natural Language Inference, NLI)。其中,NLI的目标是判断一个假设句(hypothesis)是否能够从给定的前提句(premise)中逻辑推导出来,其分类结果通常分为蕴涵(entailment)、矛盾(contradiction)或中立(neutral)[24]。
为高效地处理与管理如此庞大的文本数据,必须依赖强大的深度学习(Deep Learning, DL)框架。大型语言模型(Large Language Models, LLMs) 作为当前最具代表性的深度学习架构,在几乎所有NLP任务中(包括文本分类)均取得了显著成功。然而,尽管多数LLM先在通用语料上进行预训练,再针对具体任务进行微调,但在某些情况下,其性能仍未达到预期,特别是在领域特定文本(domain-specific text)的微调任务中。领域文本往往包含高度专业化的词汇、特有的语法结构以及数据分布不均衡等特征,使得模型泛化与迁移面临挑战 [6, 27, 29]。
因此,本系统性文献综述(Systematic Literature Review, SLR)旨在应对上述挑战,梳理领域特定文本分类中的研究进展,并提出未来的研究方向。
**研究目标(Aims)
• 探讨预训练语言模型(Pre-trained Language Models, PLMs)在领域特定文本分类中的应用; • 系统分析文本分类技术的演进,重点关注领域特定语境下的最新进展; • 对比传统与现代文本分类方法,特别强调基于Transformer的模型; • 对现有PLM相关研究进行分类,并提出该领域的技术体系化分类法(taxonomy); • 比较LLM在不同领域文本分类任务中的性能表现; • 通过实验分析通用PLM(BERT)与领域特定PLM(SciBERT、BioBERT)在生物医学句子分类中的表现; • 识别领域特定文本分类中的潜在研究方向。
**研究贡献(Contributions)
• 系统性文献综述(SLR):本研究系统回顾了2018年至2024年1月间发表的41篇文献,聚焦于PLM在领域特定文本分类中的应用,严格遵循PRISMA规范(系统综述与荟萃分析首选报告规范),确保综述过程的科学性与透明性。 • 传统与现代方法的比较:本文对传统与现代文本分类技术进行了对比分析,重点阐述了基于Transformer架构的模型,以展示该领域方法论的演化趋势。 • 技术分类体系(Taxonomy)构建:根据不同类型的PLM对现有研究进行了归类,构建了领域特定文本分类的技术图谱,为研究者提供了系统的参考框架。 • 跨领域性能分析:汇总了LLM在多个领域(如生物医学、金融、核工程、人道主义、社会科学、材料科学等)的文本分类表现,揭示不同模型在特定语境下的优势与局限。 • 挑战与关键问题:深入讨论了LLM在领域特定文本分类中的主要挑战,如领域语料不足、高计算成本、专业词汇与语法差异等问题。 • 关键发现与领域挑战总结:针对主要领域与方法类别,总结了当前研究的核心发现及未解决问题。 • 模型适配与效率优化洞察:分析了迁移学习、激活微调(activation fine-tuning)、基于提示的学习(prompt-based learning)等先进技术在提升模型性能方面的效果。 • 案例研究:通过在生物医学领域的句子分类任务中对BERT、BioBERT与SciBERT进行实证对比,探讨了领域特定预训练的有效性。 • 未来研究方向:提出未来的研究展望,包括高效领域自适应技术的开发、计算资源优化、高质量领域数据集的构建,以及模型偏差与透明性相关的伦理问题。
**论文结构
本研究首先在第2节提出PLM与领域特定任务的技术分类体系(SLR概览见图1); 第3节回顾文本分类技术的发展,涵盖传统方法与现代语言模型研究; 第3.3节分析LLM用于文本分类的挑战与关键考量, 第3.4节重点讨论领域特定语境下的PLM; 第4节探讨不同的领域特定文本分类技术; 第4.5节呈现LLM在文本分类中的对比研究; 第5节报告BERT、SciBERT与BioBERT在生物医学句子分类中的性能分析与可视化结果; 最后,在第7节与第8节总结研究局限,并提出未来研究方向。