语义分割是图像理解中最基础的任务之一,具有悠久的研究历史,因此也诞生了多种不同的方法。传统方法通常从零开始训练模型,这需要大量的计算资源和训练数据。然而,随着开放词汇语义分割(即要求模型识别超出训练类别之外的目标)的发展,获取大规模精细标注的数据变得成本高昂且难以实现。因此,研究者开始转向零训练的方法,利用已有的模型来完成任务,而这些已有模型原本用于更易获取数据的任务。
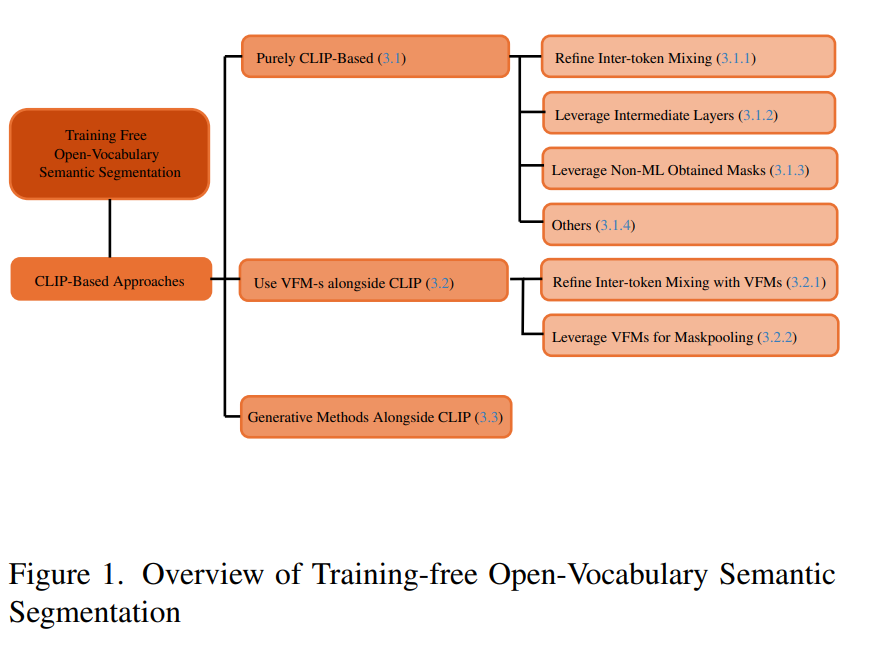
本综述将系统回顾训练自由的开放词汇语义分割的发展历程、关键概念、方法演化及当前最新研究成果,重点介绍如何利用现有的多模态分类模型来实现该任务。我们首先对任务定义进行简要介绍,随后梳理常见的模型范式,并详细介绍30余种代表性方法,它们大致可分为以下三大研究方向:纯基于 CLIP 的方法、结合辅助视觉基础模型的方法,以及依赖生成式方法的方案。
接着,我们将探讨当前研究中存在的局限与潜在问题,并提出一些尚未深入探索的未来研究方向。我们希望本综述能够为新进入该领域的研究者提供良好的入门材料,并激发更多人对这一方向的兴趣。
关键词:语义分割,开放词汇,零训练
1. 引言
图像分割是计算机视觉中最活跃的研究领域之一,也是实现图像全面理解的核心组成部分。该任务在医学影像处理【38】、自动驾驶【10】、农业【44, 69】、工业检测【49, 58】等多个领域中得到了广泛应用。将图像像素划分为语义一致的类别具有悠久的研究历史,最初并不依赖机器学习技术。早期的方法包括阈值分割【43】和边缘检测【11】,随后发展为基于区域的方法【39】。一段时间内,马尔可夫随机场和条件随机场方法【24】,以及图结构方法【52】成为研究热点,直到深度学习的兴起彻底改变了格局。此后,研究先后采用了全卷积网络(FCN)【37】、编码器-解码器架构【48】、扩张卷积【13】,以及扩展 Faster R-CNN 用于实例分割的方案【22】。最新的前沿方法则转向了 Transformer 架构【14, 15, 72】,继续推动分割技术的发展。
在突破固定类别集的限制之后,研究逐渐演进到处理任意类别集合的分割任务【8, 25, 65】。开放词汇设置的实现得益于视觉-语言模型(Vision-Language Models, VLMs)的发展,这类模型能够将文本类别嵌入与图像信息共享的语义空间中,从而实现直接对比和语义匹配。这类模型虽然在效果上表现出色,但训练往往代价高昂,既需巨大的计算资源,也需庞大而昂贵的数据集。 为此,另一类研究路线开始尝试将预训练的 VLM(如 CLIP【45】)下游应用于语义分割任务,且无需额外训练。通过巧妙的结构修改【35, 60, 74】,以及对比学习中获取知识的重构与利用,研究者成功将 CLIP 等模型扩展到了密集预测任务中。
据我们所知,本综述是目前关于零训练开放词汇语义分割最全面的系统回顾。我们将现有方法按照研究方向划分,以便于理解,并对每一类方法的细节与创新进行深入分析。各类方法还将按时间顺序组织,以体现当前最先进方法背后的思维演进链条。