
Edit Less, Achieve More研究大语言模型的持续编辑问题。发现了模型中的知识共享神经元和知识专用神经元,提出通过熵引导的稀疏掩码动态定位不同知识对应的神经元,实现更加精准的编辑过程。
论文标题:Edit Less, Achieve More: Dynamic Sparse Neuron Masking for Lifelong Knowledge Editing in LLMs 论文作者:Jinzhe Liu, Junshu Sun, Shufan Shen, Chenxue Yang, Shuhui Wang 作者单位:中国科学院计算技术研究所 论文链接:https://arxiv.org/abs/2510.22139 NeurIPS 2025 代码链接:https://github.com/LiuJinzhe-Keepgoing/NMKE
摘要
终身知识编辑使得在无需进行计算成本高昂的全量重新训练的情况下,能够对大语言模型中的过时知识进行持续且精确的更新。然而,现有方法往往会在编辑过程中累积误差,导致编辑准确性与泛化能力逐步下降。为解决这一问题,我们提出Neuron-Specific Masked Knowledge Editing(NMKE),一种将神经元级归因与动态稀疏掩码相结合的新型细粒度编辑框架。借助神经元功能归因,我们识别出两类关键的知识神经元,其中知识通用神经元在不同提示下会一致地激活,而知识特定神经元会对特定提示发生激活。NMKE 进一步引入一种熵引导的动态稀疏掩码,用于定位与目标知识相关的神经元。该策略使得在更少的参数修改下,实现精确的神经元级知识编辑。来自数千次连续编辑的实验结果表明,在终身编辑中,NMKE 在维持较高的编辑成功率以及保留模型通用能力方面优于现有方法。
01引言
终身模型编辑已成为维护并迭代现代大语言模型(LLMs)的一种有效范式,它支持持续且动态的知识注入、错误修正以及敏感内容移除。例如,模型编辑可以在无需完全重新训练的情况下纠正模型中的过时知识,比如将下一届奥运会的年份从 2024 更新为 2028。一种理想的终身知识编辑方法必须在保持高编辑准确性的同时,保留模型的通用能力。以往的知识编辑方法主要分为两类:一类是集成外部参数的方法[1][2][5],另一类是直接修改模型内部参数的方法[3][4]。外部参数方法展现出较强的泛化能力,但随着编辑次数的增加,会面临不断攀升的资源开销以及逐步下降的编辑准确性。相比之下,内部参数方法通常遵循“先定位后编辑”的范式[7][8][9],具有更强的可解释性和更简洁的架构,但容易导致通用能力退化。更关键的是,这两类方法在终身编辑场景中都存在根本性限制:随着连续编辑操作的进行,误差累积会呈指数级叠加。这引出了一个迫切的研究挑战:如何设计一种方法,在兼具外部方法强泛化能力与内部方法高效率的同时,实现无性能退化的稳健终身编辑。
受这一挑战启发,我们聚焦于内部编辑方法以保证架构简化,目标是在实现高编辑准确性的同时保留模型的通用能力。以往的内部方法探索了多种定位策略,例如因果追踪、多层更新以及零空间投影,以在模型参数中识别事实性知识。如图1所示,然而,这些策略在整个层或参数块的粒度上施加修改,往往会无意中影响与目标知识无关的神经元,从而导致模型遗忘与能力崩塌。
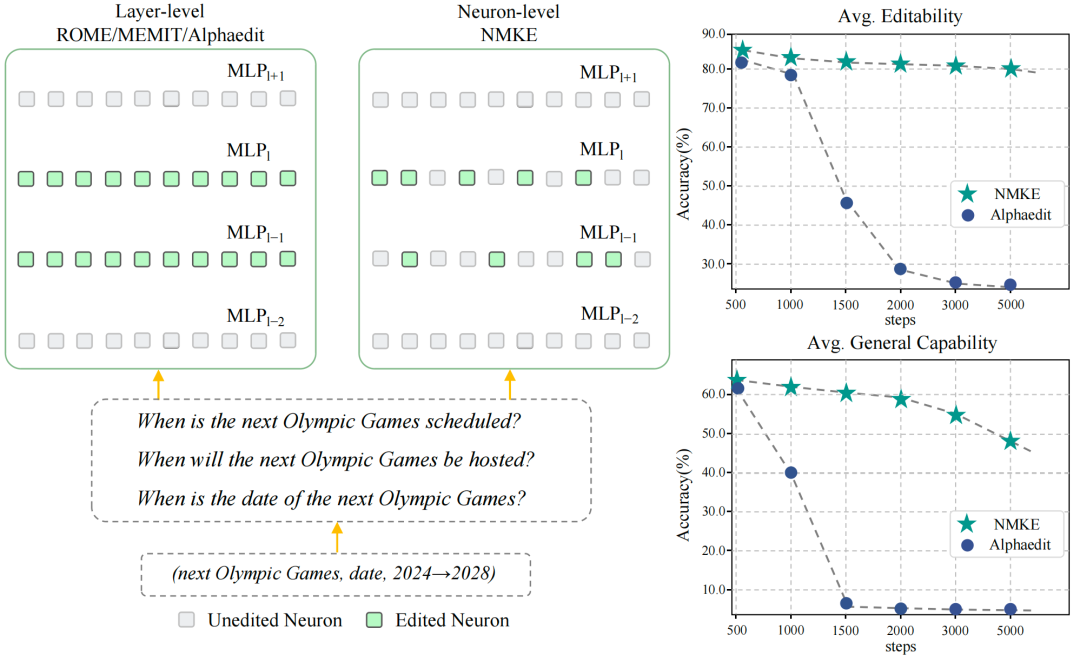
图1:左图:对比层级编辑与我们提出的神经元级编辑方法NMKE,突出二者对多层感知器(MLP)层的影响。右图:在LLaMA3-8B-Instruct模型上,不同编辑步骤下的平均可编辑性分数(包括编辑成功率、泛化成功率和定位成功率)以及平均通用能力(基于MMLU、GSM8K、CommonsenseQA和BBHZeroshot数据集的评估结果)。
在本文中,我们提出 Neuron-specific Masked Knowledge Editing(NMKE),一种新颖的细粒度知识编辑框架,该框架进行神经元级归因并构建动态稀疏掩码,以精确修改大语言模型的知识。与以往的粗粒度方法不同,NMKE 在前馈网络中采用神经元级归因,以精确量化单个神经元对基于知识的预测所作出的贡献。通过该归因分析,我们发现了两类不同的知识编码神经元:(1)知识通用神经元,其在不同提示下表现出稳定的激活并编码可泛化的信息;(2)知识特定神经元,其被选择性激活以捕捉特定语境中的语义变化。基于这一洞见,NMKE 还构建动态稀疏掩码,选择性地聚焦于与目标知识相关的最相关神经元子集。全面的实证评估表明,NMKE 通过进行最小成本的参数修改,在终身编辑中实现了最佳平衡,既确保编辑准确,又保留通用能力。我们的研究做出了如下关键贡献:
- 我们通过实验表明,终身编辑中的性能退化源于粗粒度参数更新所导致的神经元累积性扰动;在此分析基础上,我们识别出知识通用神经元与知识特定神经元在模型中存储事实性知识方面的关键作用。
- 我们提出 NMKE 这一新颖的细粒度编辑框架,它利用神经元级归因与动态稀疏掩码,精确定位并仅修改与更新知识最相关的那些神经元,从而显著降低对模型的非预期扰动。
- 通过在数千次连续编辑上的严格评估,我们表明 NMKE 在终身编辑场景中能够在保持较高编辑成功率的同时,一贯优于现有方法,并同步保留模型能力。
02. 问题表述
**
**
终身模型编辑能够在预训练语言模型中实现持续的知识更新,在无需完整重训练的前提下维持模型准确性并修正错误。形式化地,设
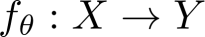
为一个参数为θ的语言模型。在序贯编辑过程中,第t步编辑会接收一个编辑请求集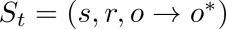
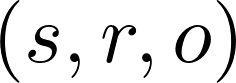
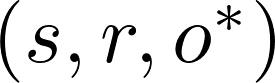
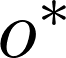
分别表示原始对象和目标对象。模型通过编辑函数E进行更新,即
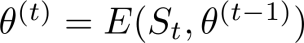
,其目标是:对于所有
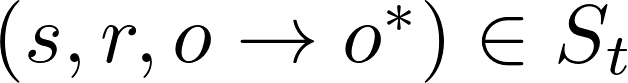
,编辑后的模型需满足
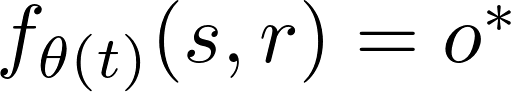
;同时,对于未编辑输入
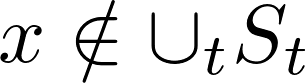
,模型输出应尽可能与更新前的结果保持一致。终身模型编辑的核心挑战在于,在实现高编辑准确性的同时,最大限度减少对未编辑知识的干扰。
03. 方法概述
**
**
本节介绍神经元特异性掩码知识编辑(NMKE),这是一种细粒度的知识编辑框架,它利用神经元级归因并构建动态稀疏掩码。3.1 节将介绍神经元级归因方法,通过神经元激活情况和掩码行为,揭示知识神经元之间的功能差异,并识别出知识通用神经元与知识特定神经元。3.2 节将介绍一种基于熵的动态掩码策略,用于筛选最小干预子集。 3.1 神经元级归因方法 3.1.1神经元级归因 受文献[32]启发,我们采用静态归因方法估算神经元的重要性。单个神经元对预测token的贡献,通过其激活受到扰动时对数概率的增量来量化。具体而言,我们将扰动过程表述为:
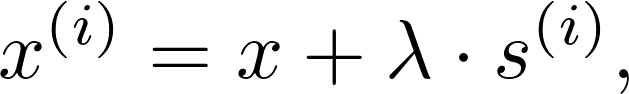
其中λ为放大系数,用于缩放扰动强度。随后,我们利用解嵌入矩阵
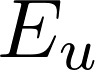
将输入x和经扰动后的输入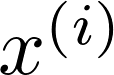
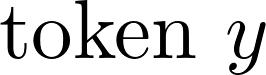
的对数概率增量:
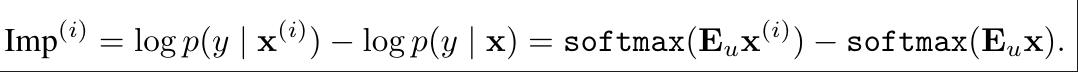
在实际应用中,针对每个编辑提示,我们会批量计算神经元的重要性分数,最终得到一个神经元重要性矩阵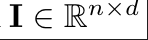
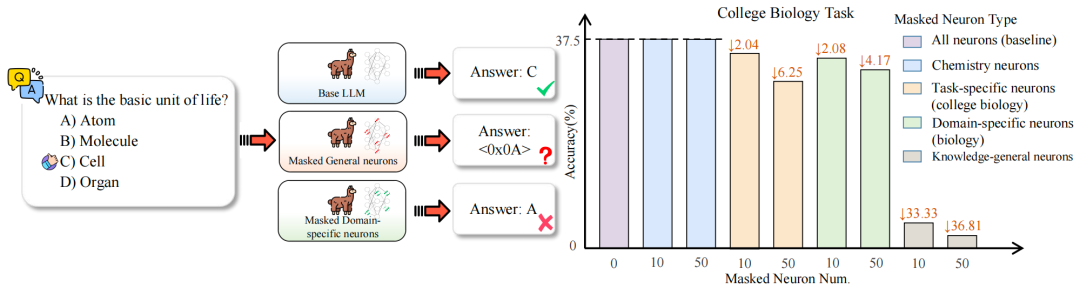
图2:左图:神经元掩码对多项选择题任务性能的影响。右图:在MMLU子任务中,对不同类型神经元进行掩码后的性能变化——其中对知识通用神经元的掩码导致性能大幅下降,尤其在大学物学准确率方面,而对领域特定神经元的掩码仅造成极小幅度的性能退化。↓表示准确率下降,下降幅度以百分比形式呈现。 3.1.2 神经元功能作用 为探究终身知识编辑中模型性能退化的原因,我们在LLaMA2-7B模型上开展了归因实验。具体而言,我们分析了Transformer块中前馈网络层在MMLU数据集各类任务中的神经元激活情况,重点关注大学及高中阶段的生物学和化学任务。基于跨任务激活模式,FFN神经元可分为三类:在所有任务中均会激活的知识通用神经元、在某一学科领域内激活的领域特定神经元,以及仅在单个任务中激活的任务特定神经元。 我们发现,知识通用神经元的数量最多,其次是领域特定神经元,任务特定神经元最为稀少。为评估不同类型神经元的功能作用,我们开展了掩码实验:对每类神经元中归因分数最高的前10个和前50个神经元进行消融,并评估MMLU子任务上的性能变化。如图2所示,对知识通用神经元进行掩码会导致模型性能严重退化,输出无意义结果(例如括号、停用词或错乱符号):消融前10个神经元时,准确率从37.5%降至4.17%,下降幅度达↓33.33%;消融前50个神经元时,准确率降至0.69%,下降幅度为↓36.81%。相比之下,对同一领域对应的任务特定神经元进行掩码仅导致轻微性能下降(↓2.04%和↓6.25%),而对不同领域对应的领域特定神经元进行掩码则几乎无影响。这些结果表明,大型语言模型中的知识并非均匀分布,而是稀疏地集中在少量神经元中。 基于上述观察,我们将神经元的功能作用归纳为两类以指导知识编辑,即知识通用神经元和知识特定神经元。具体而言,在语义相似的提示中表现出稳定激活的神经元被定义为知识通用神经元,而在特定提示中表现出强烈的局部化激活且归因分数较高的神经元被称为知识特定神经元。知识特定神经元包含领域特定神经元和任务特定神经元。每一步的模型编辑都应针对这部分神经元子集,排除无关的知识特定神经元。 3.2 动态稀疏掩码
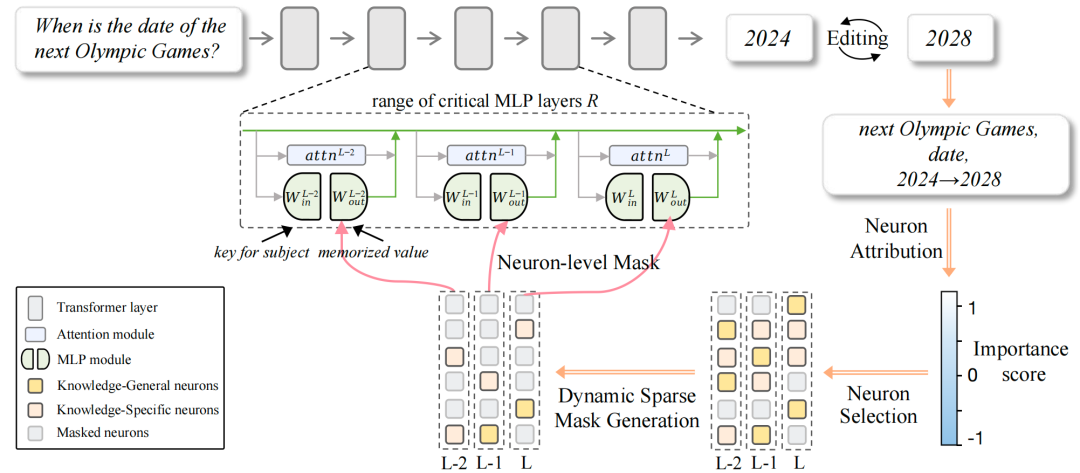
图3 NMKE的整体框架。通过神经元级归因与动态稀疏掩码,选择性更新知识通用神经元和知识特定神经元,在实现精准知识编辑的同时,保持模型的通用能力。
为定位知识编辑相关的神经元,我们提出一种动态稀疏掩码机制,该机制能自适应筛选出对目标知识表征起主要贡献作用的神经元子集。具体而言,设
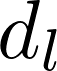
表示该层的神经元数量。两类神经元的核心区别在于:知识通用神经元在不同提示中表现出稳定的激活,而知识特定神经元仅对特定提示表现出选择性激活。通过分析归因分数的分布特征,我们即可区分这两类神经元。 3.2.1 类型特异性选择分数 知识通用神经元由于其编码核心知识的特性,在各类提示中均表现出稳定的激活,因此会产生持续为正的归因分数。这类神经元可通过统计其在多个提示中的正向归因分数数量来识别:

其中

表示指示函数,

知识特定神经元由于其编码任务特定知识的特性,至少在一个提示中会被激活,因此在特定提示中会产生显著的归因分数。这类神经元可通过计算其在所有提示中的最大归因分数来识别:
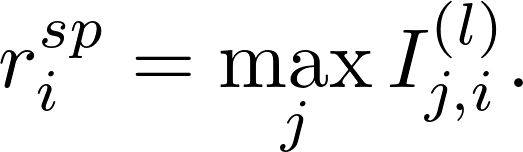
3.2.2 类型特异性选择比例
为筛选出知识通用神经元和知识特定神经元的子集,我们基于神经元的选择分数 和

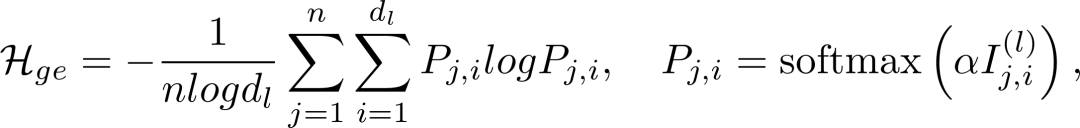
其中温度系数α用于调节分数差异。平均熵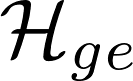
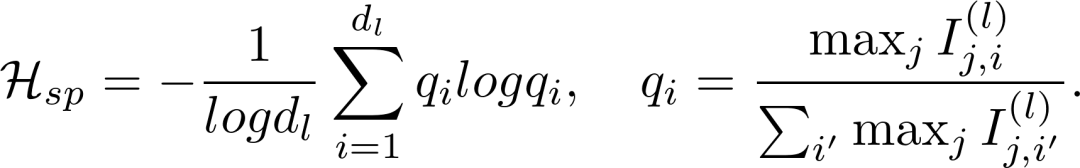
这些熵值反映了不同提示批量中相关神经元的占比。在实际应用中,我们通过常数缩放系数
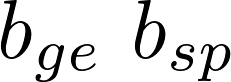

和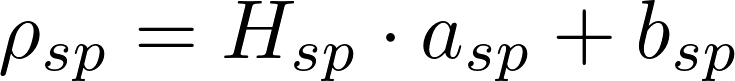
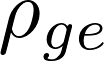
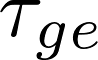
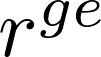
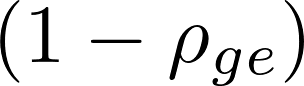
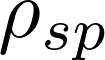
确定阈值与候选神经元。通过该选择过程,构建二值稀疏掩码


这种混合选择机制通过纳入不同神经元的功能作用,实现了对神经元级编辑的灵活控制。该方法仅选择性更新与待编辑知识相关的神经元,能够在保留无关神经元知识结构的同时完成精准编辑。如图3所示,我们提出了一种神经元级知识编辑框架NMKE(神经元特异性掩码知识编辑),将参数更新限制在功能重要的多层感知器神经元子集上,从而实现精准且低干扰的知识注入。我们沿用AlphaEdit[9]的方法构建优化流程,利用掩码(m)对参数更新矩阵进行掩码操作。
05. 实验结果
本方法从持续编辑性能和已编辑大语言模型的泛化能力维持两个方面进行综合评估。在知识编辑性能方面,本课题采用两个标准基准:用于问答的ZsRE[10]和用于事实更正的CounterFact[7]数据集。报告三项关键指标:可靠性(编辑成功率)、泛化性(对编辑提示词的泛化能力)以及局部性(局部性保持)。在泛化能力方面,本方法采用覆盖数学推理、问答与代码生成的五个下游任务:MMLU[11]、GSM8K[12]、CommonsenseQA[13]、BBH-Zeroshot[14]和 HumanEval[15]。本方法与多种基线方法进行比较,涵盖外部与内部参数方法,包括ROME[7]、MEMIT[8]、WISE[4]和 AlphaEdit[9]等主流基线方法。

图 2编辑后大语言模型的泛化能力
图 2评估了在进行1-2000次编辑步骤后,由多种方法编辑的ZsRE和CounterFact数据集上,LLaMA-3-8B-Instruct的泛化能力。总体而言,结果显示,现有方法的泛化能力会随着编辑次数增加而迅速退化。仅在进行100次编辑后,FT就会破坏大模型在GSM8K和HumanEval上的泛化能力;而ROME与MEMIT在超过500次编辑时也出现显著性能下滑。作为当前最先进的方法,AlphaEdit在层级编辑过程中由于持续修改与目标无关的知识神经元,其泛化能力也会逐渐下降。比如在T=1500时,AlphaEdit的问答性能显著下降,数学与编程能力几乎完全丧失。相较之下,本方法能在两个数据集上的终身编辑过程中有效保持大模型的泛化能力,并在T>1000的情况下显著优于所有基线。其优异表现归功于其动态稀疏掩码机制,该机制将被编辑的参数限制在局部范围内,最大程度减少对模型内部表征的扰动。
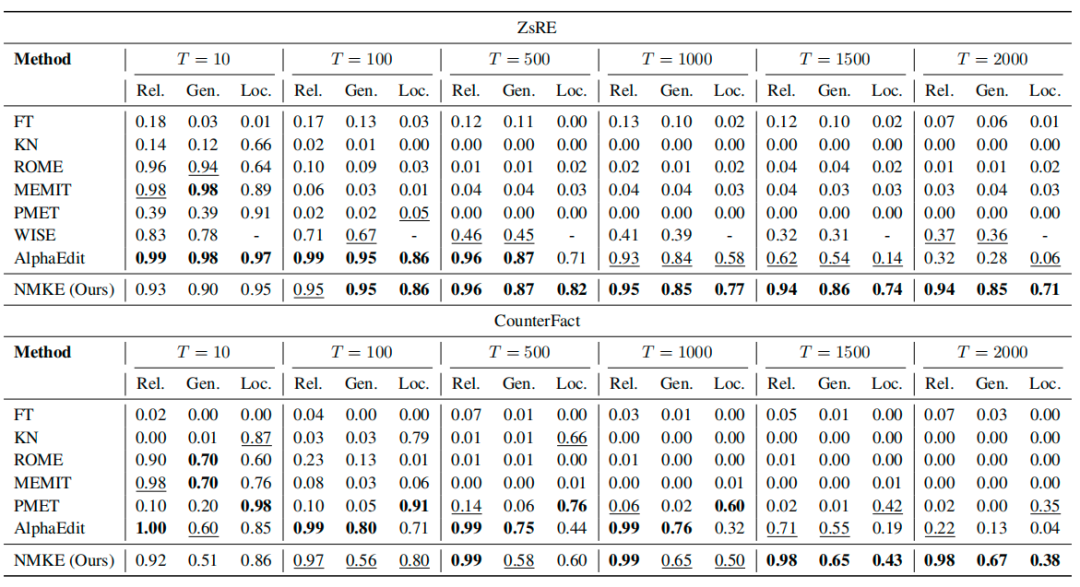
表 1持续编辑性能
表 1展示了在LLaMA3-8B-Instruct上,对2000个从ZsRE与CounterFact数据集中随机抽样的样本以批量大小为1进行顺序编辑时的终身知识编辑结果。大多数方法(如FT、KN、ROME 和 MEMIT)在T=100次编辑之后出现显著性能退化。WISE通过添加外部模块而不修改内部参数,局部性以 “-” 标示,但在完成2000次编辑后,其知识编辑成功率下降了0.46。AlphaEdit在顺序编辑过程中表现不稳定,且在T>1500时出现灾难性遗忘:其编辑成功准确率在 ZsRE上下降了0.67,在CounterFact上下降了0.78。相比之下,本方法在两个数据集上都展现出更强的终身知识编辑能力。这种稳健性源于我们细粒度的神经元级编辑策略:精确锁定相关的神经元子集,从而避免模型崩溃。
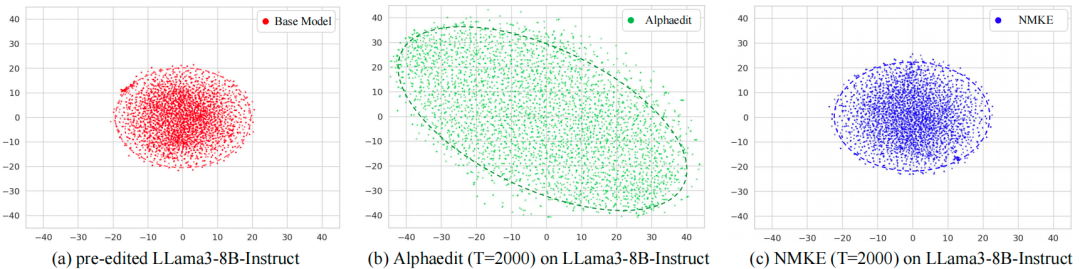
图 3 编辑对模型内部参数分布的影响
接下来我们进一步进行消融实验的研究,以分别评估方法中神经元级动态稀疏掩码的有效性。为分析不同方法对模型内部参数的影响,我们使用t-SNE可视化第8个FNN层中下投影权重的分布偏移。我们将未编辑的 LLaMA3-8B-Instruct与其经AlphaEdit和本方法在ZsRE上顺序执行2000次编辑后的版本进行比较。如图 3所示,未编辑的LLaMA3-8B-Instruct呈现出紧凑的权重分布,表明其参数结构稳定。AlphaEdit使权重分布相较原始分布出现显著偏离,在t-SNE空间中呈现更为分散且扭曲的几何形态,存在较大的分布漂移。相比之下,本方法保持更为紧凑的结构,并与原始分布高度一致,反映出最小的参数偏移。这些结果表明,相较于AlphaEdit,本方法对模型内部参数的扰动更小,这证明了其更强的编辑稳定性与更低的模型参数干扰。
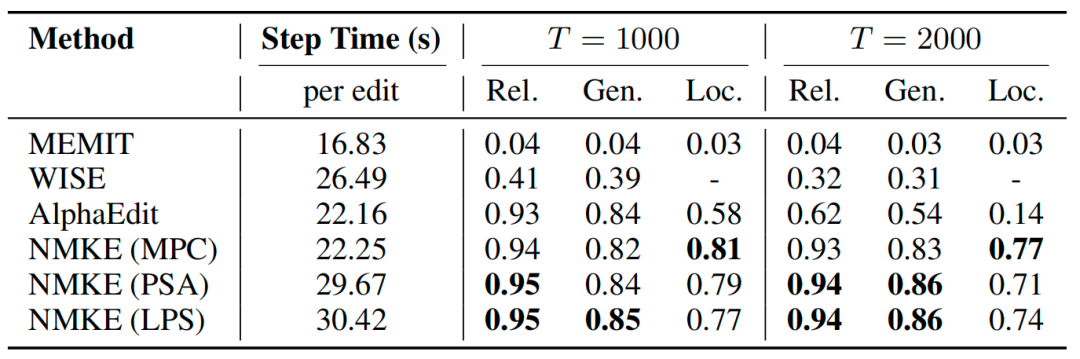
表 2编辑效率 为量化归因成本,我们在顺序编辑设置下报告每次编辑的运行时间,包含具有竞争力的多种基线方法,以及采用三种归因策略配置的神经元级动态稀疏掩码编辑方法:MLP投影系数(MPC)、概率归因(PSA)和对数概率归因(LPS)。 表 1显示,MPC是效率最高的变体,每次编辑仅产生约0.2s的额外开销;而性能最优的变体LPS虽在每次编辑上增加约8s的开销,但仍具备可实践性并带来显著改进。总体而言,本方法是一个灵活的框架,支持不同复杂度的归因方法,能够在不同场景下在质量与效率之间取得平衡。
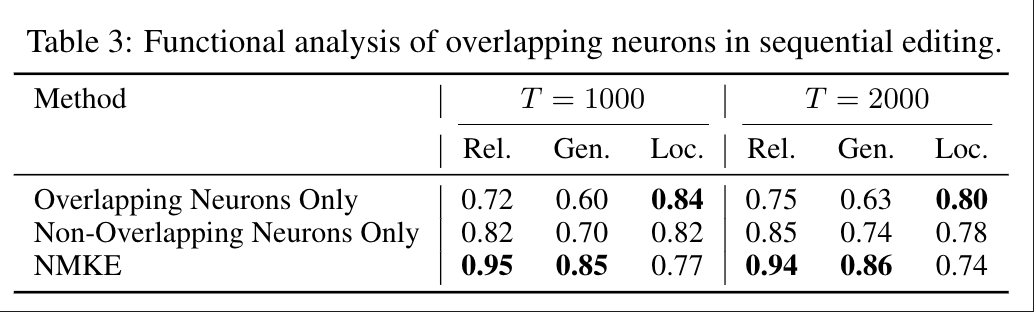
表3 重叠神经元的影响
重叠神经元的影响
为探究重叠神经元的影响,我们分别仅使用重叠神经元或仅使用非重叠神经元开展编辑实验。表3结果显示,重叠神经元在编辑成功率与局部性之间起到权衡调节作用。仅使用重叠神经元进行编辑可实现最强的局部性,但会导致可靠性与泛化性出现中度下降;仅使用非重叠神经元进行编辑虽能提升编辑成功率与泛化性,却会削弱局部性。NMKE通过熵引导的比例将两者相结合,在(T=1000)和(T=2000)时均实现了最优的综合平衡,印证了其在序列编辑场景下的稳定性。
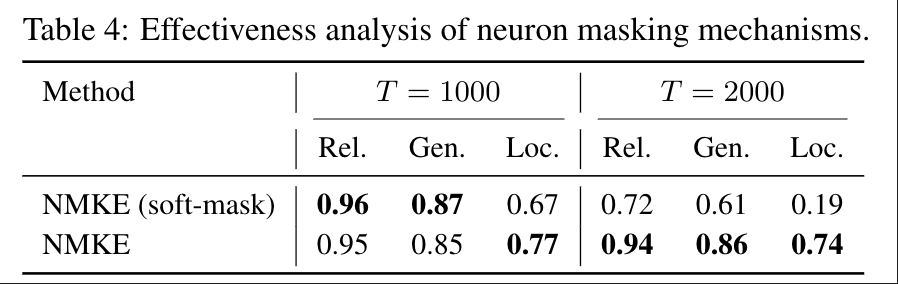
表4 神经元掩码分析
为评估离散神经元更新机制的有效性,我们将二值掩码与软掩码变体进行对比。NMKE的软掩码变体根据每个神经元的归因分数缩放其更新幅度,从而保持神经元状态的连续性。如表4所示,软掩码在准确率和泛化性上与NMKE基本相当,但其密集且无差别的更新会降低局部性。相比之下,NMKE将更新限制在稀疏且感知知识的神经元子集上,从而保持稳定性并实现可靠的局部性。
06. 结论
**
**
本课题主要针对持续编辑任务进行研究,提出了一种细粒度的神经元级动态稀疏掩码编辑方法,它利用神经元级归因和动态稀疏掩码来实现精确编辑。通过识别并针对知识通用神经元和知识特异性神经元,将更新限制在相关的神经子集内,有效减少了干扰。实验表明,该方法在编辑成功率和泛化保留方面优于现有方法,特别是在涉及数千次编辑的终身编辑场景中,其他方法会出现累积性能下降,而该方法则表现出色。这种优异性能源于我们的神经元级干预方法,该方法在确保编辑成功的同时保留了通用能力,为终身编辑提供了一种很有前景的解决方案。
参考文献:
- Mitchell E, Lin C, Bosselut A, et al. Memory-based model editing at scale[C]//International Conference on Machine Learning. PMLR, 2022: 15817-15831.
- Hartvigsen T, Sankaranarayanan S, Palangi H, et al. Aging with grace: Lifelong model editing with discrete key-value adaptors[J]. Advances in Neural Information Processing Systems, 2023, 36: 47934-47959.
- Yu L, Chen Q, Zhou J, et al. Melo: Enhancing model editing with neuron-indexed dynamic lora[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 38(17): 19449-19457.
- Wang P, Li Z, Zhang N, et al. Wise: Rethinking the knowledge memory for lifelong model editing of large language models[J]. Advances in Neural Information Processing Systems, 2024, 37: 53764-53797.
- Zheng C, Li L, Dong Q, et al. Can we edit factual knowledge by in-context learning?[J]. arXiv preprint arXiv:2305.12740, 2023.
- De Cao N, Aziz W, Titov I. Editing factual knowledge in language models[J]. arXiv preprint arXiv:2104.08164, 2021.
- Meng K, Bau D, Andonian A, et al. Locating and editing factual associations in gpt[J]. Advances in neural information processing systems, 2022, 35: 17359-17372.
- Meng K, Sharma A S, Andonian A, et al. Mass-editing memory in a transformer[J]. arXiv preprint arXiv:2210.07229, 2022.
- Fang J, Jiang H, Wang K, et al. Alphaedit: Null-space constrained knowledge editing for language models[J]. arXiv preprint arXiv:2410.02355, 2024.
- Levy O, Seo M, Choi E, et al. Zero-shot relation extraction via reading comprehension[J]. arXiv preprint arXiv:1706.04115, 2017.
- Hendrycks D, Burns C, Basart S, et al. Measuring massive multitask language understanding[J]. arXiv preprint arXiv:2009.03300, 2020.
- Cobbe K, Kosaraju V, Bavarian M, et al. Training verifiers to solve math word problems[J]. arXiv preprint arXiv:2110.14168, 2021.
- Talmor A, Herzig J, Lourie N, et al. Commonsenseqa: A question answering challenge targeting commonsense knowledge[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 4149-4158.
- Suzgun M, Scales N, Schärli N, et al. Challenging big-bench tasks and whether chain-of-thought can solve them[C]//Findings of the Association for Computational Linguistics: ACL 2023. 2023: 13003-13051.
- Chen M. Evaluating large language models trained on code[J]. arXiv preprint arXiv:2107.03374, 2021.