摘要—大语言模型(LLMs)及多模态大语言模型正在改变事件抽取(EE):提示与生成往往能在零样本或少样本设置中产生结构化输出。然而,基于LLM的流程面临实际部署的差距,包括在弱约束下的幻觉、长上下文及跨文档中脆弱的时间与因果关联,以及有限上下文窗口内受限的长程知识管理。我们认为,事件抽取应被视为一个系统组件,为以LLM为中心的解决方案提供认知支架。事件模式与槽位约束为知识落地与验证创建了接口;以事件为中心的结构可作为分步推理的受控中间表示;事件链接支持基于图谱的检索增强生成(RAG)实现关系感知检索;事件存储则提供了超越上下文窗口的可更新事件记忆与智能体记忆。本综述涵盖文本与多模态场景下的事件抽取,梳理了任务与分类体系,追溯了从基于规则与神经模型到指令驱动与生成框架的方法演进,并总结了形式化定义、解码策略、架构、表示、数据集与评估方法。同时,我们回顾了跨语言、低资源及特定领域场景,并强调了构建可靠事件中心系统的开放挑战与未来方向。最后,我们概述了LLM时代核心的开放挑战与未来路径,旨在推动事件抽取从静态抽取演变为面向开放世界系统的结构可靠、即插即用的感知与记忆层。
I. 引言
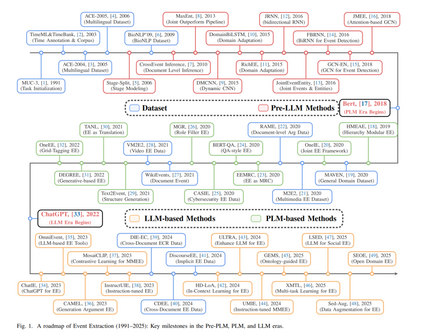
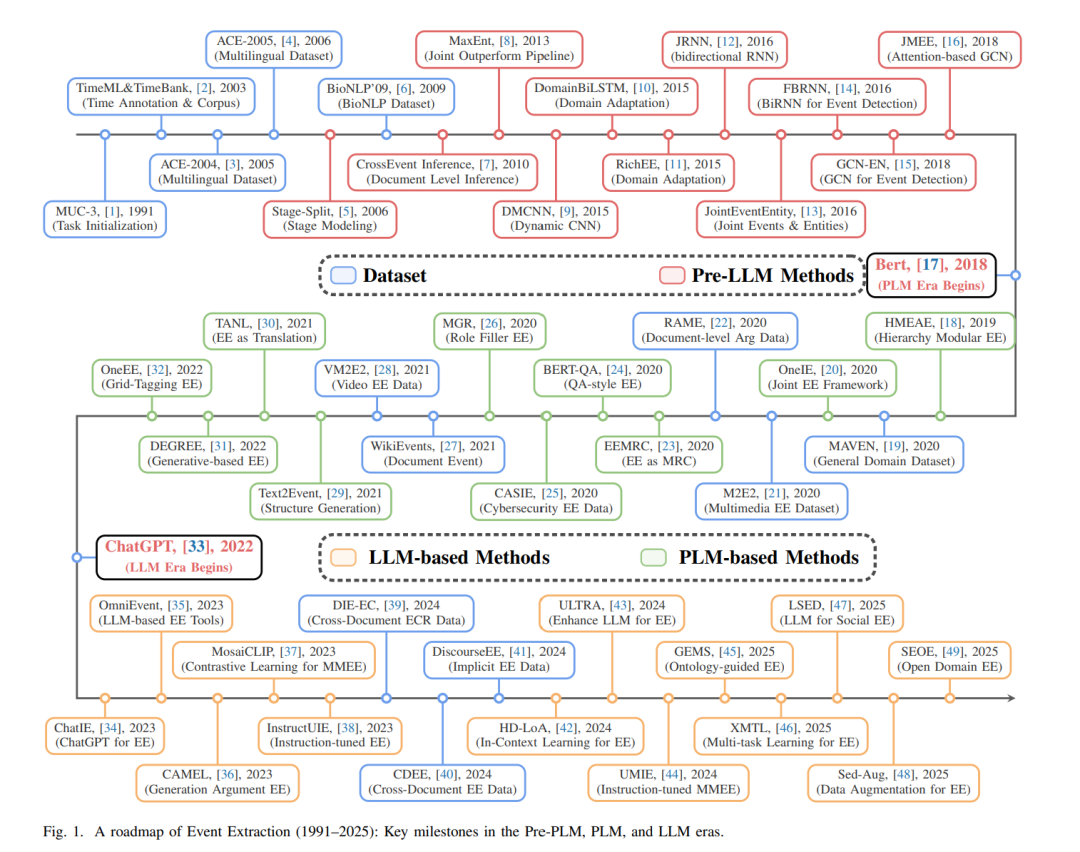
事件抽取(EE)是自然语言处理中的一项核心任务,旨在从非结构化文本中识别事件触发词、事件类型及参与者角色,并将其组织成可计算的结构化表示[27]。与实体或关系层面上的静态事实不同,事件捕捉发生了什么、谁参与其中、何时何地发生、如何展开以及随之产生何种结果。这种能力在需要追踪和解读现实世界动态的应用场景中至关重要,包括金融风控与舆情监控、临床病程追踪、态势感知以及公共安全与应急预警。过去二十年间,研究界开发了许多数据集和基准,并推动了方法从基于规则和特征工程向基于神经与图模型的演进[12],[16],[27]。这些努力也支撑了事件知识库和事件图谱的构建与应用,使得事件抽取成为更广泛信息抽取领域中的一个关键支柱。 大语言模型(LLMs)的兴起正在重塑信息抽取的实践。以往需要针对特定任务进行训练的模型,现在通常可以通过提示通用大语言模型来直接产生类似于结构化记录的输出,有时甚至在零样本或少样本设置下也能实现[50],[51]。这一转变引发了一个不可避免的问题:在大语言模型能够端到端处理文本并生成结构化输出的时代,事件抽取是否仍然作为一个独立的研究方向存在必要? 在许多实际部署中,主流做法正日益趋向于将原始文本直接输入大语言模型,而不是先抽取结构化事件,再基于这些结构进行下游推理和决策。因此,事件抽取可能看起来不如从前核心,甚至可能被误认为端到端生成技术可以轻易替代。 本文认为,大语言模型并未削弱事件抽取的价值。相反,它们将事件抽取从一个以任务或模型为中心的问题,推向一个系统级的结构化接口与约束层。关键在于,实际部署不仅关心生成答案,还关心满足可靠性、可追溯性和长程知识管理等系统要求。在这些要求下,仅依赖无约束的端到端生成会暴露出巨大的认知差距。首先,生成输出具有概率性。没有明确的结构约束,模型可能产生幻觉,且错误可能在多步骤流程中累积[52]。其次,当证据分散在长上下文或多个文档中时,模型往往难以维持时间顺序、因果链和角色共指之间的稳定链接。这使得推理过程脆弱且难以审计。第三,基于相似性的检索无法保证获取精确的时间或因果关系,而有限的上下文窗口无法容纳开放环境中持续的经验流。因此,仅仅堆叠更多文本通常不足以支撑长期规划和一致的行为。 事件抽取提供了一种结构化的补充,直接针对这些系统级的差距。因为事件抽取的输出是显式、受限且可计算的,它们可以在以大语言模型为中心的系统中充当中间表示和外部记忆。从这个意义上讲,事件抽取从一个静态的预测任务演变为一个认知支架。首先,对于可靠性,事件模式与槽位约束为知识落地和验证提供了具体接口,缩小了自由形式生成的空间,并为检查和纠正提供了锚点。其次,对于推理,事件链将叙事分解为离散的步骤,可以作为类似思维链推理的受控中间结构,提高可控性和可复现性[53]。第三,对于知识访问和记忆,事件及其时间、因果和角色链接使得检索能够超越简单的相似性匹配,迈向基于图的关系可导航的检索增强生成[54],[55]。这种组织形式进一步支持可更新的事件记忆,这对于需要长程规划且不受上下文溢出约束的智能体非常有用[56]。因此,在大语言模型时代,事件抽取的价值不仅在于它是获取结构化输出的一条路径,更在于它为验证、推理、检索和智能体记忆提供了结构化的骨干支撑。 基于这一视角,本文沿着任务、数据集与评估以及方法范式的轴线重新审视事件抽取。我们从文本事件抽取的经典定义和分解开始,回顾代表性数据集、评估协议和指标,然后总结建模方法从基于规则和传统学习方法到神经、生成及指令驱动框架的演进。我们进一步讨论多模态和跨文档设置如何扩展事件抽取的边界。在此基础上,我们探讨新兴的生成模型和智能体系统如何在实践中重塑事件抽取的功能角色,重点阐述其与大语言模型的常见协作模式,包括结构化约束、可验证的工作流、基于图的检索和外部记忆。最后,我们基于应用需求提炼出开放挑战和未来方向,旨在为设计可靠、可控和可部署的以事件为中心的智能系统提供参考。 本综述其余部分结构如下。第II节介绍事件抽取的任务定义和分类体系,统一文本事件抽取的核心子任务,并将讨论扩展到视觉、视频和语音等多模态场景。第III至第VI节回顾方法与建模路径,涵盖基于规则和传统学习方法、深度学习方法,以及大语言模型和多模态大语言模型时代的指令驱动与生成范式,同时介绍常见的任务形式化、解码策略、系统架构和表示设计。第VII节总结数据集、评估指标和工具链。第VIII节讨论多样化的应用场景,如跨语言和低资源场景、不同粒度以及垂直领域。第IX节概述开放挑战和未来方向。第X节为全文总结。