

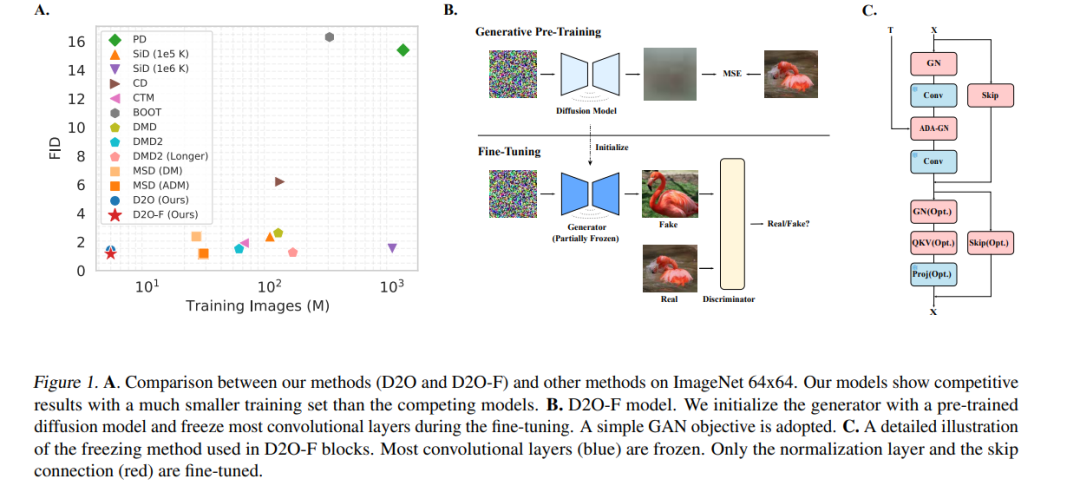
扩散蒸馏是一种广泛使用的技术,旨在降低扩散模型的采样成本,然而该方法通常需要大量训练,而且学生模型的性能往往有所下降。近期研究表明,引入 GAN 目标可以缓解这些问题,但其背后的机制尚不清晰。 在本工作中,我们首先识别出蒸馏过程中的一个关键限制:教师模型与学生模型在步长设置和参数数量上的不匹配会导致它们收敛到不同的局部最优,从而使得直接模仿变得次优。我们进一步证明,单独使用 GAN 目标、而不依赖蒸馏损失,就可以克服这一限制,并足以将扩散模型转化为高效的一步生成器。 基于这一发现,我们提出可以将扩散训练视为一种生成式预训练方法,为模型赋予可以通过轻量级的 GAN 微调所激发的生成能力。为验证这一观点,我们通过在冻结 85% 参数的情况下微调一个预训练模型,实现了一个一步生成模型,在仅使用 20 万张图像的情况下就取得了优异性能,并在使用 500 万张图像时接近当前最先进水平(SOTA)。我们还进一步提出了一种频域分析方法,用以解释扩散训练中获得的一步生成能力。 总体而言,我们的研究为扩散模型训练提供了一个全新的视角,强调其作为一种强大的生成式预训练过程的作用,并可为构建高效的一步生成模型奠定基础。
成为VIP会员查看完整内容
相关内容

Arxiv
42+阅读 · 2023年4月19日
Arxiv
152+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
152+阅读 · 2023年3月29日