

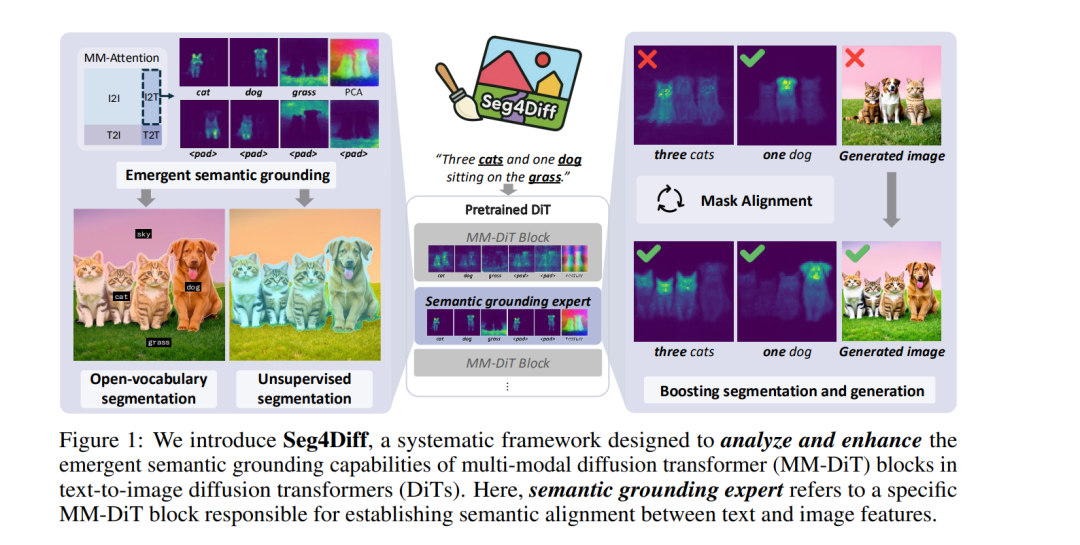
文本到图像的扩散模型(text-to-image diffusion models)擅长将语言提示转化为逼真的图像,其核心在于通过跨模态注意力机制隐式地对文本概念进行语义绑定。近年来,多模态扩散 Transformer(MM-DiT)进一步发展了这一能力,通过在拼接的图像与文本 token 上引入联合自注意力,实现了更丰富且更具扩展性的跨模态对齐。然而,对于这些注意力图在图像生成过程中具体如何以及在哪些位置发挥作用,仍缺乏细致的理解。 在本文中,我们提出 Seg4Diff(Segmentation for Diffusion),一个系统化框架,用于分析 MM-DiT 的注意力结构,重点考察特定层如何将语义信息从文本传播到图像。通过全面分析,我们识别出一个 语义绑定专家层(semantic grounding expert layer)——这是一个特定的 MM-DiT 模块,它能够稳定地将文本 token 与空间一致的图像区域对齐,自然地产生高质量的语义分割掩码。 进一步地,我们展示了:在具备掩码标注图像数据的条件下,结合轻量化微调方案,可以增强这些层的语义分组能力,从而同时提升分割性能与生成图像的保真度。我们的研究结果表明,语义分组是扩散 Transformer 的一种涌现属性,并且可以通过选择性放大来同时推动分割与生成性能的发展,为连接视觉感知与生成的统一模型铺平道路。https://cvlab-kaist.github.io/Seg4Diff
成为VIP会员查看完整内容
相关内容

专知会员服务
15+阅读 · 2022年3月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
15+阅读 · 2020年3月31日
相关VIP内容
专知会员服务
15+阅读 · 2022年3月19日
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日
Arxiv
15+阅读 · 2020年3月31日