
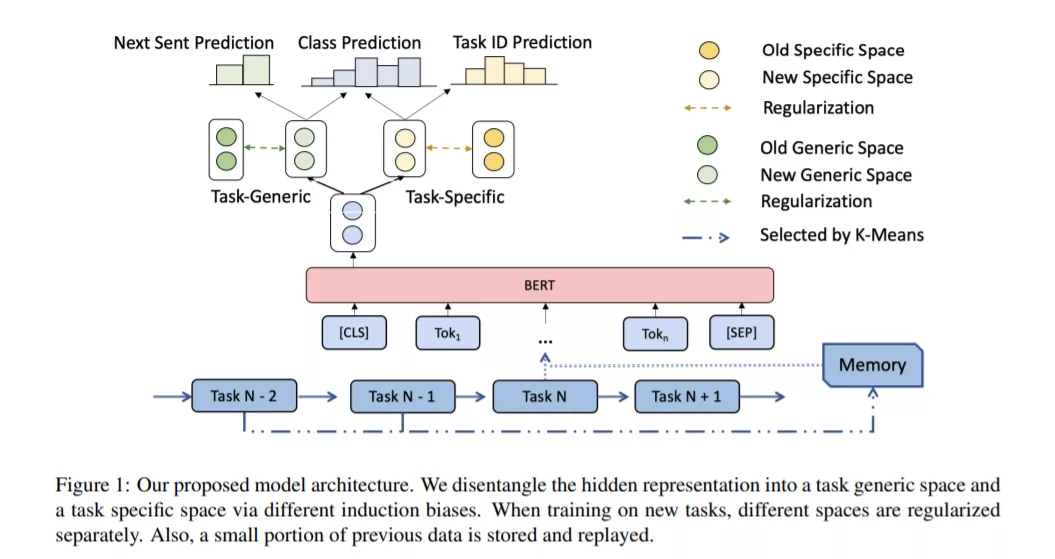
持续学习变得越来越重要,因为它使NLP模型能够随着时间的推移不断地学习和获取知识。以往的持续学习方法主要是为了保存之前任务的知识,并没有很好地将模型推广到新的任务中。在这项工作中,我们提出了一种基于信息分解的正则化方法用于文本分类的持续学习。我们提出的方法首先将文本隐藏空间分解为对所有任务都适用的表示形式和对每个单独任务都适用的表示形式,并进一步对这些表示形式进行不同的规格化,以更好地约束一般化所需的知识。我们还介绍了两个简单的辅助任务:下一个句子预测和任务id预测,以学习更好的通用和特定表示空间。在大规模基准上进行的实验证明了我们的方法在不同序列和长度的连续文本分类任务中的有效性。
成为VIP会员查看完整内容
相关内容

Arxiv
3+阅读 · 2018年4月18日


相关VIP内容
相关资讯