大型语言模型(Large Language Models,LLMs)凭借其强大的语义理解与生成能力,在自然语言处理领域取得了显著成功。然而,其“黑箱”特性限制了其在结构化推理与多跳推理中的表现。相比之下,文本属性图(Text-Attributed Graphs,TAGs)通过显式的关系结构和丰富的文本上下文提供了结构化知识,但往往缺乏语义深度。 近期研究表明,将 LLM 与 TAG 相结合能够产生互补效应:既能提升 TAG 的表征学习能力,又能增强 LLM 的推理性与可解释性。本文首次从协同(orchestration)视角系统性回顾了 LLM–TAG 融合研究,提出了一种新的分类体系,涵盖两个基本方向: * LLM for TAG:利用大型语言模型促进基于图的任务; * TAG for LLM:利用结构化图数据增强语言模型的推理能力。
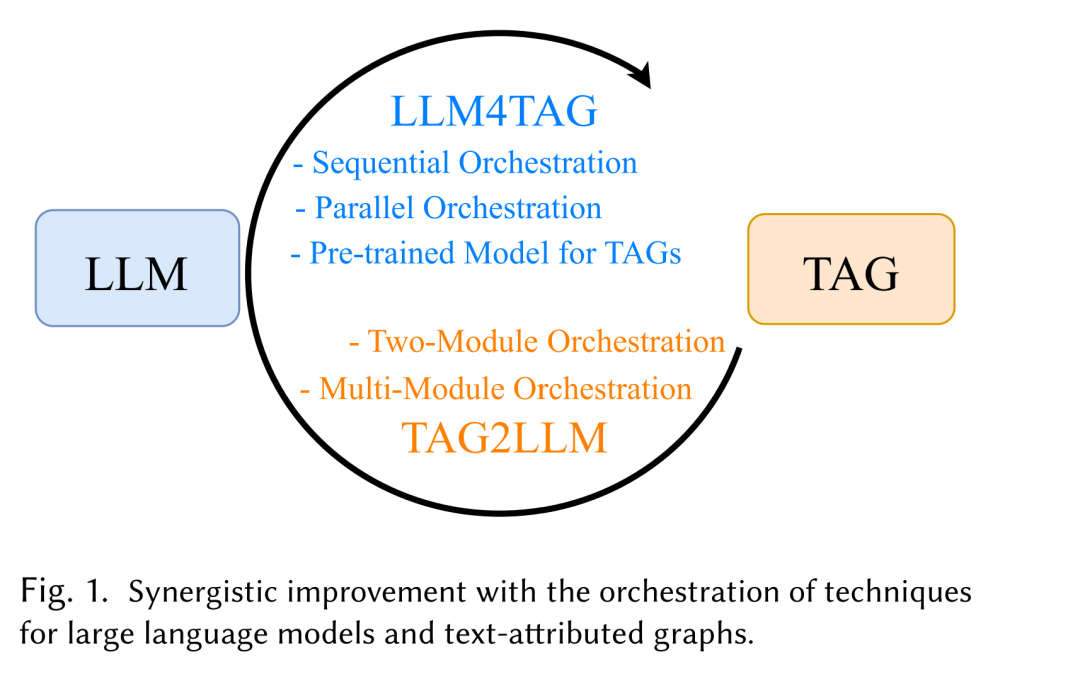
我们将融合策略划分为顺序式(sequential)、并行式(parallel)与多模块式(multi-module)三类框架,并讨论了在 TAG 特定的预训练(pretraining)、提示设计(prompting)及参数高效微调(parameter-efficient fine-tuning)等方面的最新进展。 除方法论外,本文还总结了实证研究的关键发现,整理了可用数据集,并概述了在推荐系统、生物医学分析以及知识密集型问答等领域的多样化应用。最后,我们指出了当前面临的开放挑战与未来值得探索的研究方向,旨在为语言与图学习交叉领域的后续研究提供系统性指导。 基于 Transformer 的架构 [200] 的兴起彻底革新了自然语言处理(NLP)领域。以大型语言模型(Large Language Models,LLMs)为代表的 GPT 系列 [2, 16, 158, 160],建立在 Transformer 解码器架构之上,并在大规模语料上进行预训练,展现出卓越的能力,使得 LLM 成为迈向通用人工智能(Artificial General Intelligence,AGI)的基础性一步。与之形成对比的是更为紧凑的语言模型(Language Models, LMs¹),如 BERT 系列 [39, 74, 131, 169],基于 Transformer 编码器结构,在需要细粒度上下文理解与精确语义表征的任务中表现优异,从而成为特定领域研究与应用中的关键组件。 在现实世界中,大量关键信息以文本形式存储,涵盖科学文献、社交媒体帖子及生物记录等 [80, 110, 182]。这些文本数据往往蕴含丰富的相互关系,可自然地建模为文本属性图(Text-Attributed Graphs,TAGs) [235],其中节点、边或整个图均可附加文本属性。因此,TAGs 同时包含两种数据类型:文本属性与图结构。例如,在引文网络中,节点代表附带摘要或全文的论文,边表示反映语义相关性的引用关系;在推荐系统中,TAGs 可表示用户与物品,节点附带用户画像或商品描述,边则捕获用户-物品交互、共购行为或基于评论的情感信息;在化学研究中,化合物可被建模为 TAGs,其中原子或分子节点附有文本化学性质描述或文献知识。对这类兼具结构性与文本性的关系进行精确建模与分析,对于文本分类 [258]、个性化推荐 [264]、分子发现 [90] 等下游任务至关重要。 近年来,研究者对LLM 与 TAG 的协同融合兴趣日益浓厚,原因在于二者在处理文本与图结构数据方面的互补性:LLM 擅长解析与生成文本,而 TAG 能捕获数据中复杂的关系结构。图 1 展示了 LLM 与 TAG 技术在处理文本与图结构数据时的多种协同方式。这些融合式方法不仅提升了 TAG 相关任务的表现(即 LLM for TAGs),也增强了 LLM 的推理能力(即 TAG for LLMs),在多个研究领域取得了显著进展,包括图增强生成(graph retrieval-augmented generation)[153]、知识密集型问答 [152]、幻觉问题缓解 [65] 以及科学发现 [64, 174] 等。例如,[246] 基于电子病历(Electronic Medical Records, EMRs)构建 TAG,将医学术语视为节点,并根据上下文窗口内的共现关系建立边 [58]。LLM 与 TAG 技术的结合提升了语义与结构表征的质量,使医学术语分类更加准确且可解释。 受 LLM–TAG 融合研究热潮的推动,本文从**协同编排(orchestration)**视角出发,系统综述二者在推理能力与表征学习方面的互补提升机制。我们从两个核心范式——LLM4TAG 与 TAG4LLM——出发,对现有工作进行系统化组织,并提出了新的协同框架分类体系:
★ LLM for TAG
将 LLM 应用于 TAG 的文本属性部分,可生成语境丰富的嵌入(context-rich embeddings),结合拓扑感知的图学习机制,实现更优的图表征学习。 * 在**顺序式协同框架(sequential orchestration)中 [75],LLM 先对文本特征进行编码,其输出再输入到显式建模图连接性的图学习模型中; * 在并行式协同框架(parallel orchestration)**中 [55],LLM 与图学习模型并行运行,分别处理文本与拓扑结构,随后通过对比学习等技术对齐嵌入以支持下游任务; * 此外,部分研究 [12, 224] 借鉴 LLM 的训练范式,如自监督预训练与微调,以增强 TAG 学习; * 尤其是 TAG 预训练模型 [227] 将 LLM 的自监督目标、微调策略及提示设计(prompt design)机制迁移至图领域,构建出更具表达性与泛化性的 TAG 框架。
★ TAG for LLM
TAG 以结构化的显式文本整合形式,为符号推理提供了清晰的支撑,有助于缓解 LLM 在透明性与决策性方面的不足。这一问题源于 LLM 将庞大知识隐式嵌入其参数中 [247],导致模型的不透明性,从而影响可解释性与事实准确性。诸如“思维链提示(Chain-of-Thought Prompting)” [218] 等方法虽能一定程度上生成解释,但仍存在幻觉 [92] 与不准确性 [202],尤其是在多跳推理场景下。通过将 LLM 的推理过程锚定于 TAG,可生成更可靠、可解释的输出,从而减轻这些局限性 [152]。 我们将 TAG for LLM 方法分为两类: * 双模块协同框架(two-module orchestration) [23]; * 多模块协同框架(multi-module orchestration) [62]。 两者均基于相同原理:将 TAG 提供的符号化、拓扑感知信息与 LLM 的语言能力相结合,从而生成更透明、可解释且事实精确的输出。
与现有 LLM–TAG 综述的区别
本文是首个从模型协同与互补增强视角系统总结 LLM 与 TAG 模型的综述,重点关注数据与技术如何在最新研究中被组织与协同利用。 * 范围拓展:不同于以往仅聚焦节点层面、将文本视为节点属性的 TAG 综述 [26, 49, 95, 116, 146, 164],本文系统涵盖 LLM4TAG 与 TAG4LLM 的所有细节,并扩展至 边级(edge-level) 与 图级(graph-level) 表征,重点探讨文本信息如何增强关系(边)与结构化知识(图,尤其是知识图谱 KGs [152, 153])。 * 方法覆盖:除框架综述外,还纳入了 TAG 自监督预训练与 Transformer 基模型等最新研究,为图基础模型的构建提供了更全面的探索。 * 实证总结:相比仅局限于少数模型的分析 [75, 258],本文系统整合了多篇相关研究的实验观察与经验性洞见,总结出从近期进展、挑战与限制到未来发展方向的三维度分析。 * 多模态与应用扩展:本文进一步引入多模态 TAG(multimodal TAG),并对实际应用进行了系统梳理,涵盖推荐系统、生物医学、知识问答等领域;同时,整理并发布相关数据集资源,为未来研究提供支持。
本文的主要贡献
全新视角的系统综述:从协同编排角度系统梳理 LLM 与 TAG 的融合机制,揭示其互补提升关系。 1. 方法体系分类:系统分类并总结 LLM 提升 TAG 性能与 TAG 增强 LLM 推理的关键策略与底层机制。 1. 实验观察与洞见总结:综合近期研究的实验结果,从三个维度总结出可操作的经验性洞察。 1. 资源与未来方向:整理数据集与工具资源,提出涵盖数据管理、模型创新与架构探索的未来研究路线。
论文结构
本文结构安排如下: * 第 2 节介绍研究背景与预备知识; * 第 3 节综述 LLM 在 TAG 建模中的协同框架、实际应用及实证洞察; * 第 4 节回顾 TAG 在 LLM 推理增强中的框架与应用; * 第 5 节讨论开放挑战与未来机遇; * 第 6 节给出总结。