
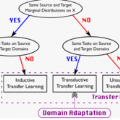
虽然在许多领域产生并提供了大量的未标记数据,但获取数据标签的成本仍然很高。另一方面,用深度神经网络解决问题已经变得非常流行,但目前的方法通常依赖大量的标记训练数据来实现高性能。为了克服注释的负担,文献中提出了利用来自同一领域的可用未标记数据的解决方案,称为半监督学习;利用相似但又不同领域的已有标记的数据或训练过的模型,称为领域自适应。本教程的重点将是后者。领域自适应在社会上也越来越重要,因为视觉系统部署在任务关键应用中,其预测具有现实影响,但现实世界的测试数据统计可以显著不同于实验室收集的训练数据。我们的目标是概述视觉领域适应方法,这一领域在计算机视觉领域的受欢迎程度在过去几年中显著增加,这可以从过去几年在顶级计算机视觉和机器学习会议上发表的大量的相关论文中得到证明。

https://europe.naverlabs.com/eccv-2020-domain-adaptation-tutorial/
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2020年12月13日
Arxiv
5+阅读 · 2017年11月24日
相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年12月13日
Arxiv
5+阅读 · 2017年11月24日