大型语言模型(Large Language Models, LLMs)凭借其在文本生成与推理方面的卓越能力,已经彻底改变了自然语言处理领域。然而,这些模型在实际应用中仍面临关键挑战,包括幻觉生成、知识过时以及领域专长有限等问题。检索与结构化增强生成(Retrieval And Structuring, RAS Augmented Generation)通过将动态信息检索与结构化知识表示相结合,有效缓解了这些局限性。 本综述工作:(1) 系统考察了外部知识访问的检索机制,包括稀疏、稠密以及混合检索方法;(2) 探讨了文本结构化技术,如分类体系构建、层次化分类和信息抽取,这些方法能够将非结构化文本转化为有组织的表示形式;(3) 分析了这些结构化表示如何通过基于提示的方法、推理框架和知识嵌入技术与LLMs集成。此外,本文还指出了在检索效率、结构质量和知识集成方面的技术挑战,并强调了多模态检索、跨语言结构以及交互式系统等研究机遇。
这一全面的综述为研究人员和实践者提供了有关 RAS 方法、应用及未来发展方向的重要见解。
1 引言
大型语言模型(Large Language Models, LLMs)已经彻底改变了自然语言处理领域,在从文本生成到复杂推理等任务中展现出前所未有的能力 [2, 17]。这些模型基于海量文本数据进行训练,在理解上下文、生成类人化的响应,以及通过最少指令适应多样化任务方面表现出显著优势 [190, 258]。然而,在真实应用场景中部署时,LLMs 仍面临若干关键挑战:它们可能生成看似合理但事实错误的信息(即幻觉)[82, 86],依赖可能已经过时的训练数据 [124, 171],并且在专业领域中缺乏足够的知识专长 [195, 227]。
在知识密集型应用中,这些局限性尤为明显,因为此类应用对准确性和可靠性要求极高。虽然 LLMs 擅长模式识别和文本生成,但它们在保持事实一致性和获取最新信息方面存在困难。在科学研究、医疗健康或技术等专业领域,LLMs 常常缺乏实现可靠性能所需的精确和细致的知识 [50, 95, 145]。
为应对这些挑战,研究者提出了 检索增强生成(Retrieval-Augmented Generation, RAG)框架,它通过在生成响应前从外部知识源检索相关信息来增强 LLM 的能力 [64, 124]。通过将生成与检索文档相结合,RAG 有助于减少幻觉并使模型能够访问其参数中未包含的最新信息。然而,传统的 RAG 方法仍存在根本性局限:它们通常仅处理非结构化的文本片段,而未能利用结构化知识;其检索结果中常包含非原子化信息,可能误导 LLMs [50, 95, 261];并且在应对需要多跳推理或特定领域知识组织的复杂查询时表现不足 [303, 306]。
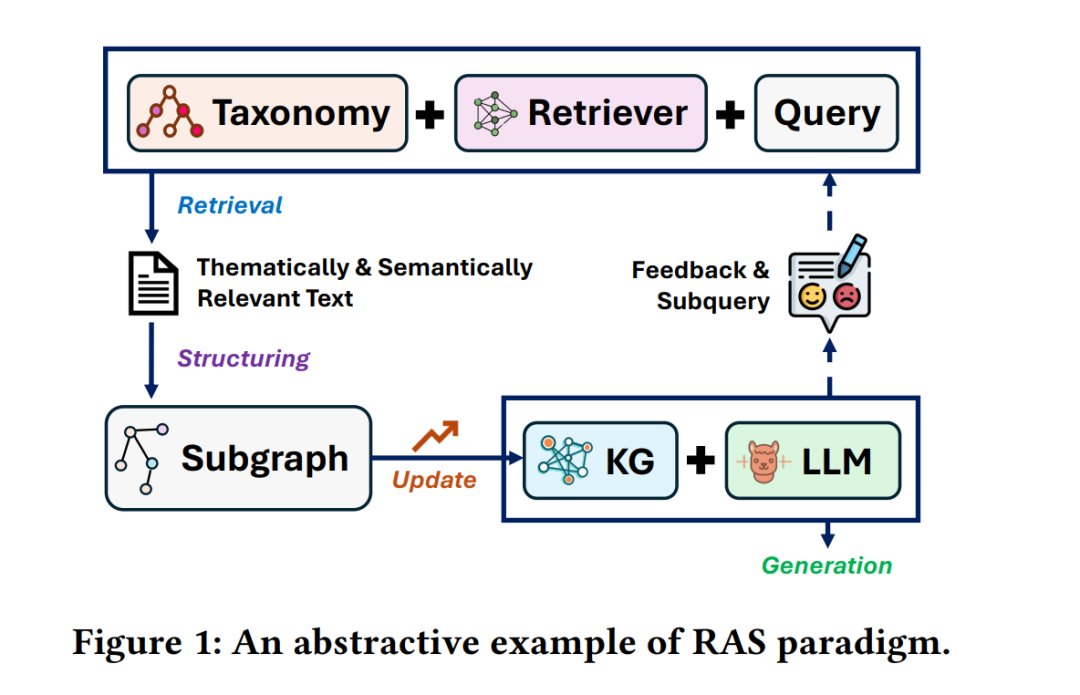
检索与结构化增强生成(Retrieval And Structuring, RAS)作为一种更强大的范式应运而生,它通过将动态信息检索与结构化知识表示相结合,有效克服了上述局限。RAG 为 LLMs 与外部信息建立连接奠定了基础,而 RAS 在此之上进一步扩展其能力:引入知识结构化技术,将非结构化文本转化为有组织的表示形式,如分类体系、层次结构和知识图谱 [46, 224, 299]。这些结构化表示不仅有助于组织检索到的信息,还能引导检索过程,并为验证 LLM 输出提供框架。
最新的 RAS 研究成果已经展示了显著的性能提升:包括与 LLM 推理模式更契合的新型检索策略 [63, 252],以及构建高质量知识表示的方法改进 [90, 116]。检索与结构化机制的深度融合,为多个领域带来了新的可能性:在科学研究中,RAS 系统能够在保持技术准确性的同时综合信息 [37, 275];在电子商务中,它们可生成个性化推荐 [26, 279];在医疗健康中,则能提供可靠的上下文信息 [110, 259]。 尽管如此,要充分发挥 RAS 的潜力,仍需解决若干挑战:包括大规模高效检索 [238, 314]、保持高质量的知识表示 [306]、将结构化信息无缝集成到 LLM 推理过程 [151, 230],以及在计算开销与实时性能之间实现平衡 [48, 128]。
本文对 RAS 的组成部分、应用和未来方向进行了全面的综述。我们首先介绍 LLMs 与检索增强生成的基础知识,随后系统讨论先进的检索机制与文本结构化方法(如分类体系构建、层次化分类与信息抽取)。接着,我们分析这些结构化表示如何与 LLMs 集成以提升推理与适应能力,进一步考察其在不同领域的应用,最后总结尚存的技术挑战与未来研究机遇。