
神经信息处理系统大会(Conference on Neural Information Processing Systems,简称NeurIPS),是机器学习和计算神经科学领域的顶级国际会议。NeurIPS 2025将在美国圣地亚哥(12月2日至12月7日)和墨西哥城(11月30日至12月5日)两地举办。本系列文章将分期介绍自动化所在本届会议上的录用论文成果,欢迎交流探讨。
01. DiCo: 重振卷积网络以实现可扩展且高效的扩散建模********
DiCo: Revitalizing ConvNets for Scalable and Efficient Diffusion Modeling ★Spotlight
**作者:**艾雨昂, 樊齐航, 胡雪峰, 杨振恒, 赫然, 黄怀波 本研究围绕扩散模型的高效生成展开。近年来,基于Transformer的扩散模型(DiT)在图像生成领域表现突出,但其全局自注意力机制带来了巨大的计算开销。本文通过深入分析预训练的DiT模型发现,自注意力在生成任务中多以局部建模为主,长距离依赖的作用有限,这提示我们有可能设计出更高效的替代架构。 为此,我们提出了 Diffusion ConvNet (DiCo),一种完全基于卷积的扩散模型骨干结构。DiCo利用轻量化的点卷积与深度卷积构建基础模块,并引入紧凑通道注意力,有效缓解了卷积网络中通道冗余问题,提升了特征多样性与表达能力。 在ImageNet条件生成实验中,DiCo-XL在256×256分辨率下实现了2.05的FID,并在512×512分辨率下取得2.53的FID,且相比DiT-XL/2实现2.7至3.1倍的加速。同时,在MS-COCO数据集上的实验表明,纯卷积的DiCo同样具备较强的文本到图像生成潜力。

DiCo在保持高效率的同时实现了优异的图像质量
**02.**分区再适应:应对预测偏差以实现可靠的多模态测试时自适应
Partition-Then-Adapt: Combating Prediction Bias for Reliable Multi-Modal Test-Time Adaptation ★Spotlight
**作者:**王国威,吕凡,丁长兴 本文针对多模态任务在测试时遇到的多模态同时域偏移问题提出了Partition-Then-Adapt(PTA)方法。现有测试时自适应(TTA)技术多集中于单一模态的域偏移,当多模态同时受到干扰时,模型难以区分可靠样本,容易出现预测偏差并导致误差积累。PTA由两部分组成:一是“分区与去偏重加权”(Partition and Debiased Reweighting, PDR),通过比较样本预测标签频率与批次平均水平,量化预测偏差并将数据划分为潜在可靠和不可靠两类,再结合置信度用分位数方法重新加权。二是“多模态注意力引导对齐”(Attention-Guided Alignment, AGA),利用可靠样本的注意力分布引导不可靠样本,通过最大均值差异正则化使模型聚焦于语义相关线索。 该方法在Kinetics50-C、VGGSound-C等多模态基准以及CMU-MOSI、CMU-MOSEI、CH-SIMS等真实数据集上均显著优于现有方法,尤其在高噪声、多模态同步域偏移场景下提升明显,并在动态环境和小批量数据情况下表现出较强鲁棒性。PTA不仅缓解了高置信但偏差大的“假可靠样本”问题,还在保持效率的同时提高了模型在多模态测试时自适应任务中的稳定性和准确性。
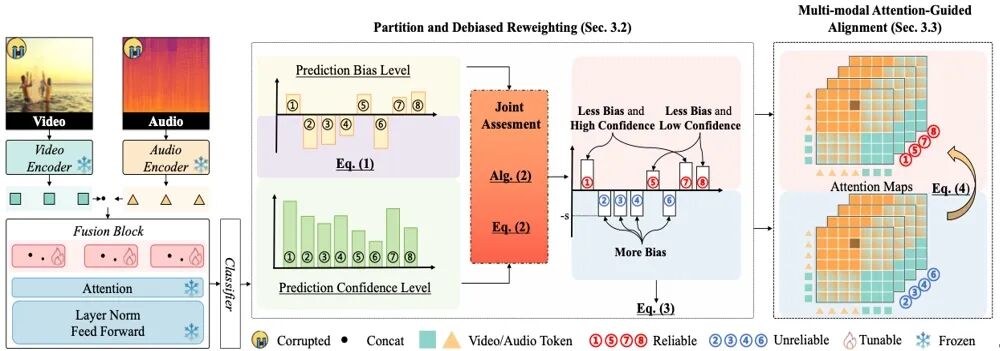
PTA方法设计
03.** **RepoMaster:面向复杂任务求解的 GitHub 仓库自主探索与理解框架
RepoMaster: Autonomous Exploration and Understanding of GitHub Repositories for Complex Task Solving ★Spotlight
**作者:**汪华灿,倪子懿,张硕,卢硕,胡森,何子扬,胡晨,林嘉烨,郭毅芙,杜云涛,吕品 代码智能体的终极目标是自主解决复杂任务。尽管大语言模型(LLM)在代码生成方面进步显著,但从零构建完整代码仓库仍具挑战,而现实任务往往需要完整仓库而非简单脚本。值得关注的是,GitHub上汇集海量开源项目,常被用作“轮子”复用于复杂任务,但现有框架如OpenHands和SWE-Agent对其仍难以有效利用:仅依赖README文件指导不足,深入探索则面临信息过载与依赖关系复杂两大核心障碍,且均受限于当前LLM的有限上下文长度。 为此,我们提出RepoMaster——一个专注于探索和复用GitHub仓库的自主智能体框架。在理解阶段,通过构建函数调用图、模块依赖图与层级化代码树,精准识别关键组件,仅向LLM提供核心要素而非完整仓库内容。在自主执行过程中,依托探索工具逐步拓展关联组件,并通过信息剪枝优化上下文使用效率。 实验结果显示,在MLE-bench-R上RepoMaster的有效提交率较最强基线OpenHands提升110%;在GitTaskBench基准中,将任务通过率从40.7%提升至62.9%,同时显著降低95%的token消耗。该框架为代码智能体高效利用现有代码资源提供了创新性解决方案。
图1. 所提RepoMaster总体流程,包括代码库搜索、代码库混合结构分析和自主探索与执行。
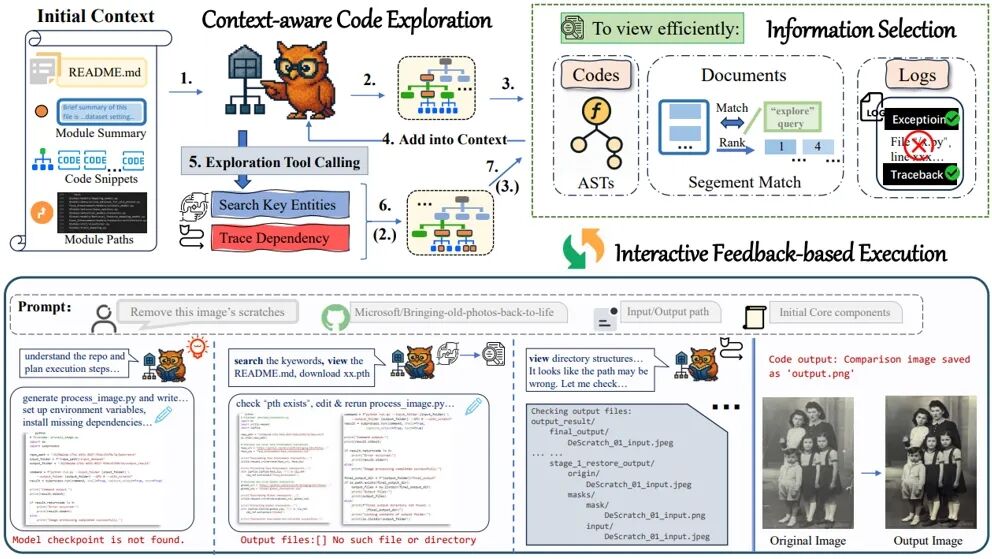
图2. RepoMaster 的自主探索–执行循环概览及示例演示。 该智能体首先对初始上下文进行分析(步骤 1),并指定需要检查的文件(步骤 2)。为提高信息获取效率,系统从该文件中提取关键信息(步骤 3),并将其附加至当前上下文(步骤 4)。在随后的探索–执行迭代过程中(步骤 6→2,步骤 7→3),智能体利用探索工具识别更多相关文件,重复基于上下文的代码探索。当收集到足够的信息后,RepoMaster 在编写与执行 “.py” 脚本之间交替进行,通过错误处理与基于反馈的调试,不断优化执行过程,直至任务完成。
04.** **进步的幻象?视觉语言模型测试时自适应方法再审视
The Illusion of Progress? A Critical Look at Test-Time Adaptation for Vision-Language Models **作者:**生力军,梁坚,赫然,王子磊,谭铁牛 视觉语言模型(VLM)的测试时适应(TTA)方法能够在无需额外标注数据的情况下提升模型在推理阶段的性能,因此受到广泛关注。然而,现有TTA研究普遍存在基准结果重复、评估指标单一、实验设置不一致以及分析不够深入等局限,这阻碍了方法间的公平比较,也掩盖了其实际优缺点。 为此,我们提出了一个面向视觉语言模型的测试时适应综合评测基准——TTA-VLM。该基准在一个统一且可复现的框架中实现了8种片段式TTA方法和7种在线TTA方法,并在15个常用数据集上对其进行了系统评估。与以往仅关注CLIP的研究不同,我们将评估范围扩展至SigLIP模型,并引入训练时调优方法以检验TTA方法的通用性。除了分类准确率,TTA-VLM还整合了鲁棒性、校准性、分布外检测能力及稳定性等多种评估指标,从而能够对TTA方法进行更全面的评估。通过大量实验,我们发现现有TTA方法相比早期开创性工作带来的性能提升有限、当前TTA方法与训练时微调方法的协同效果不佳、准确率的提升常常以模型可信度的下降为代价。
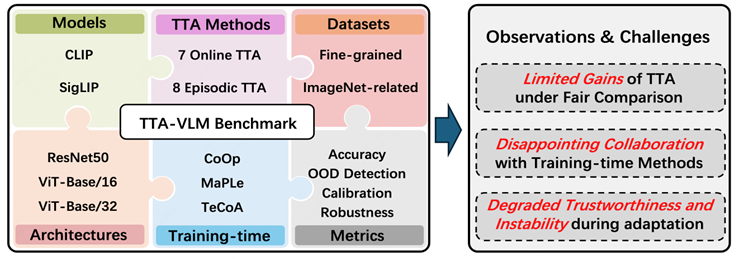
所提基准 TTA-VLM 的总体结构
05.** **思考与视觉绘图交织强化视觉-语言模型中的空间推理能力
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing **作者:**吴俊飞,关健,冯凯拓,刘强,吴书,王亮,武威,谭铁牛 传统视觉语言模型(LVLMs)普遍采用“视觉转文本”的推理范式:先将图像压缩为token序列并映射至语言空间,再交由大语言模型(LLM)进行纯文本推理。然而,受限于视觉编码器的能力与训练数据,这一过程往往丢失大量关键的细节与时空信息;同时,在冗长的文本推理链中,模型对原始视觉信号的关注也逐渐减弱,制约了其空间推理能力。 针对这一瓶颈,我们提出全新推理范式——“Drawing to Reason in Space”(空间绘图推理),让LVLMS能够像人类一样“边画边想”:在视觉空间中动态选择关键帧,并绘制参考线、标记框等辅助标注,引导视觉编码器精准捕捉时空关系,显著缓解信息损失问题。我们设计了三阶段训练框架——从冷启动建立基础绘图能力,到通过反思拒绝采样筛选高质量推理路径,最终以强化学习端到端优化任务目标,并开源模型 ViLaSR-7B。实验表明,该方法在多个空间推理基准上平均提升 18.4%;在李飞飞教授团队提出的 VSI-Bench 上,性能达到 45.4%,与 Gemini-1.5-Pro 相当,全面超越现有方法,为视觉语言模型的空间推理开辟了新路径。
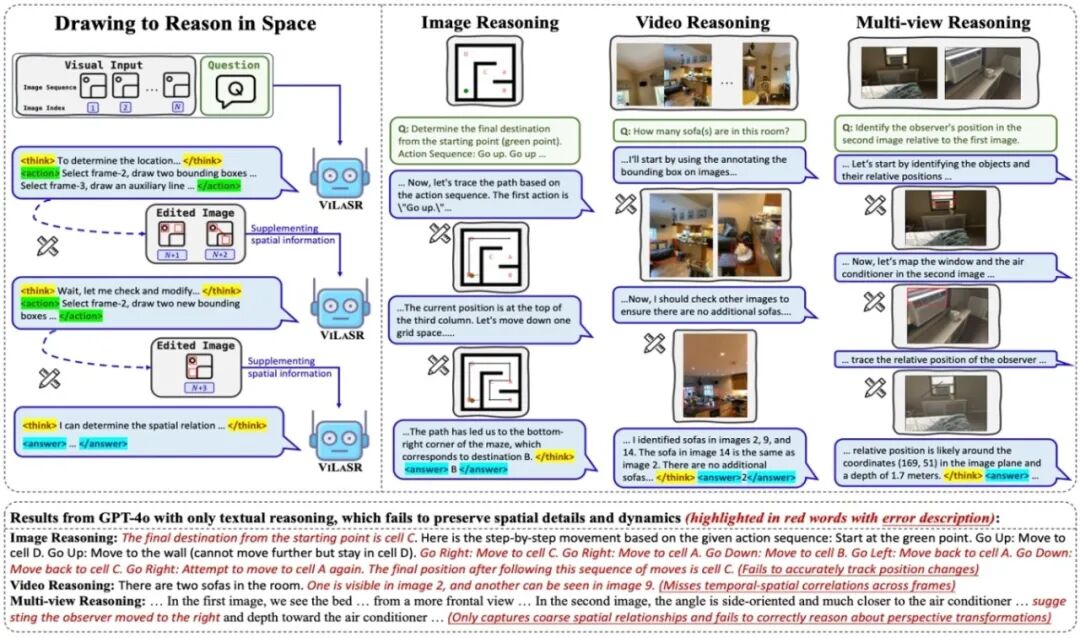
Drawing to reason in space推理范式
06.** **DAA:在测试时类发现中放大未知差异
DAA: Amplifying Unknown Discrepancy for Test-Time Discovery **作者:**刘天乐,吕凡,倪成功,张彰,胡伏原,王亮 在动态开放的真实环境中,人工智能系统不仅要保持对已知类别的识别,还必须具备在线发现新类别的能力。然而,现有测试时适应与记忆增强方法多依赖静态特征与固定原型,难以应对未知类别的干扰,导致新类识别不稳定、边界模糊和错误积累。 针对这一挑战,我们提出了面向测试时发现(Test-Time Discovery,TTD)任务,结合差异放大适配器(DAA, Discrepancy-Amplifying Adapter) 与短期记忆更新(STMR, Short-Term Memory Renewal)。DAA 在训练阶段通过模拟未知类并放大特征差异,使模型在面对未知数据时具备更强的区分力。STMR 在测试阶段动态刷新短期记忆原型,有效降低错误传播并保持已知类性能。在 CIFAR100-D、CUB-200-D 与 Tiny-ImageNet-D 等多个基准上,我们的方法在实时评估与后评估中均显著优于现有最先进方法,能清晰分离未知类并提升稳定性。这项研究为开放世界和持续学习提供了全新思路,也为医疗、自动驾驶与智能机器人等需要在线新类发现的应用奠定了技术基础。
DAA方法框架
07.** **视觉模型在图结构理解中被低估的力量
The Underappreciated Power of Vision Models for Graph Structural Understanding **作者:**赵鑫鉴, 庞威, 薛中凯, 简相如,张磊, 胥瑶瑶, 宋晓壮,吴书,于天舒 本研究探索了视觉模型在图结构理解方面尚未充分开发的潜力。图神经网络(GNN)采用局部信息聚合机制,与人类视觉感知图结构的方式存在根本差异,人类通常先把握全局结构,再关注局部细节。研究发现,将图转换为图像后,纯视觉模型在图级别基准上能达到与GNNs相当的性能,但展现出完全不同的学习模式。然而,现有的基准往往将领域特征与拓扑理解混合在一起,难以深入分析这种差异的根源,也无法单纯评估模型的结构理解能力。为此,我们提出GraphAbstract,专用于测试模型是否具备类似人类的图结构理解与泛化能力。该基准通过系统性增加图的规模来评估模型的跨尺度泛化能力,这是人类图认知的一个重要特征。 实验结果显示,视觉模型在需要全局结构理解的任务上明显优于GNN,并保持了更好的跨尺度泛化性能。值得注意的是,与使用更强大的GNN架构相比,为GNN加入位置编码等全局结构先验后,其性能和泛化性的提升更为显著。这一发现与视觉模型的天然优势共同揭示了获取全局拓扑信息是图理解成功的核心要素。本研究为设计更强大的图模型探索了新的路径。
GraphAbstract基准上不同模型的性能对比,显示视觉模型在跨尺度泛化方面的优势。
08.** 输入输出对齐的高效3D视觉-语言-动作模型**********
BridgeVLA:Input-Output Alignment for Efficienct 3D Manipulation Learning with Vision-Language Models **作者:**李沛言,陈艺翔,吴弘涛,马骁,吴祥楠,黄岩,王亮,孔涛,谭铁牛 近年来,利用预训练的视觉-语言模型(VLM)构建视觉-语言-动作(VLA)模型已成为有效的机器人操作方法。然而,现有方法主要处理2D输入,忽略了宝贵的3D信息。尽管一些最新研究提出将3D信号引入VLM以进行动作预测,但它们忽视了3D数据中固有的空间结构,导致样本效率低下。 本文提出了一种新颖的3D VLA模型——BridgeVLA,该模型具有以下特点:(1)将3D输入投影为多个2D图像,确保与VLM骨干网络的输入对齐;(2)利用2D热图进行动作预测,在输入和输出统一在一致的2D空间。此外,我们还提出了一种可扩展的预训练方法,赋予VLM骨干网络预测2D热力图的能力。大量实验表明,所提出的方法能够高效学习3D操作技能。BridgeVLA在多个基准测试中超越了现有的最先进的基线方法。在RLBench中,它的成功率显著提高(88.2% vs. 81.4%)。在COLOSSEUM中,它在泛化场景中表现出更好的性能(64.0% vs. 56.7%)。在GemBench中,它是唯一在所有四个评估设置中达到50%平均成功率的方法。在实际机器人实验中,BridgeVLA平均比最先进的基线方法提高了32%,并且能够在多个分布外设置中进行鲁棒的泛化,包括视觉干扰和未见过的语言指令。值得注意的是,在总共10多项任务中,BirdgeVLA能够针对每项任务仅用3个轨迹就能达到96.8%的成功率,显示出其卓越的样本效率。
BridgeVLA的网络结构示意图
**09. **DriveDPO:一种基于安全直接偏好优化的端到端自动驾驶策略学习方法
DriveDPO: Policy Learning via Safety DPO For End-to-End Autonomous Driving **作者:**尚书尧,陈韫韬,王宇琪,李颖彦,张兆翔 端到端自动驾驶近年来取得了显著进展,其核心思路是直接从原始感知输入中预测未来轨迹,从而绕过传统的模块化处理流程。然而,主流基于模仿学习的方法存在严重的安全隐患:它们难以区分那些“看似接近人类轨迹”但实际上存在潜在风险的轨迹。部分最新研究尝试通过回归多种基于规则的安全评分来缓解这一问题,但由于监督信号与策略优化相互割裂,最终导致性能不足。 为解决上述挑战,我们提出DriveDPO,一种基于安全直接偏好优化的策略学习框架。首先,我们将人类驾驶的相似度与基于规则的安全评分相融合,蒸馏为统一的策略分布,以实现预训练阶段的策略优化。接着,我们引入了一个迭代式的直接偏好优化(iterative DPO)阶段,将其形式化为轨迹级的偏好对齐过程。在NAVSIM基准上的大量实验证明,DriveDPO 取得了新的最先进成绩。此外,在多种复杂场景下的定性结果进一步表明DriveDPO 能够生成更加安全且可靠的驾驶行为。通过有效抑制不安全行为,我们的方法展现了在安全关键型端到端自动驾驶应用中的巨大潜力。
DriveDPO 策略学习框架的整体流程
10.** **TC-Light: 时序一致的生成式视频重渲染器
TC-Light: Temporally Coherent Generative Rendering for Realistic World Transfer **作者:**刘洋,罗传琛,汤子墨,李颖彦,杨雨然,宁远勇,范略,张兆翔,彭君然 光照和纹理编辑是世界到世界迁移的关键维度,这对于包括模拟到真实和真实到真实视觉数据的扩展以支持具身人工智能的应用来说具有重要价值。现有的技术通过生成式重新渲染输入视频来实现迁移,例如视频重新光照模型和条件世界生成模型。然而,这些模型主要局限于训练数据的领域(例如肖像),或者陷入时间一致性和计算效率的瓶颈,尤其是在输入视频涉及复杂动态和长时间的情况下。 在本文中,我们提出了 TC-Light,这是一种新颖的生成式渲染器,旨在克服这些问题。它从一个由膨胀的视频重新光照模型初步重新光照的视频开始,在第一阶段优化外观嵌入以对齐全局光照。然后在第二阶段优化所提出的规范视频表示,即独特视频张量(UVT),以对齐细粒度的纹理和光照。为了全面评估性能,我们还建立了一个长且高度动态的视频基准。大量实验表明,我们的方法能够实现物理上合理的重新渲染结果,具有出色的时序连贯性和较低的计算成本。
TC-Light算法效果示意图
11.** **可塑性的学习:脉冲神经网络中的可塑性驱动学习框架
Learning the Plasticity: Plasticity-Driven Learning Framework in Spiking Neural Networks **作者:**申国斌, 赵东城, 董一廷, 李杨, 赵菲菲, 曾毅 本研究提出了一种创新性的脉冲神经网络(SNN)学习框架,即可塑性驱动学习范式(Plasticity-Driven Learning Framework, PDLF)。传统神经网络主要关注直接训练突触权重,导致连接静态且在动态环境中适应性有限。相比之下,PDLF将重点转向学习可塑性规则本身,而非简单的权重调整。 该框架由两个核心组件构成:突触协作可塑性(SCP)和前突触依赖可塑性(PDP)。SCP通过考虑前后突触神经元活动动态调整突触强度,PDP基于前突触活动调整并引入偏置以保持稳定性。通过演化策略优化这些可塑性参数,网络能够形成独特且适应性强的可塑性规则。 实验结果表明,PDLF显著增强了SNN的工作记忆容量、多任务学习能力和泛化性能。在工作记忆任务中,PDLF使网络能够将记忆直接编码到突触权重中,无需依赖神经元活动维持记忆。在多任务强化学习中,PDLF展现出卓越的适应性,能够处理不同甚至相互冲突的任务。该框架还表现出强大的鲁棒性,能够从临时性神经损伤中恢复,并在永久性损伤情况下保持良好性能。
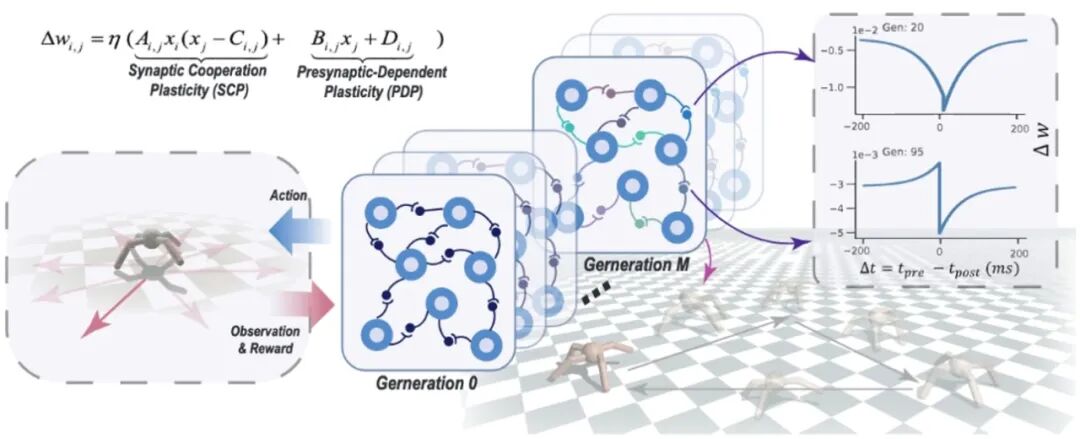
图1.PDLF框架示意图
图2.工作记忆实验设计及PDLF对工作记忆的影响
12.** **跬步:一个面向Spiking Transformer的统一基准框架
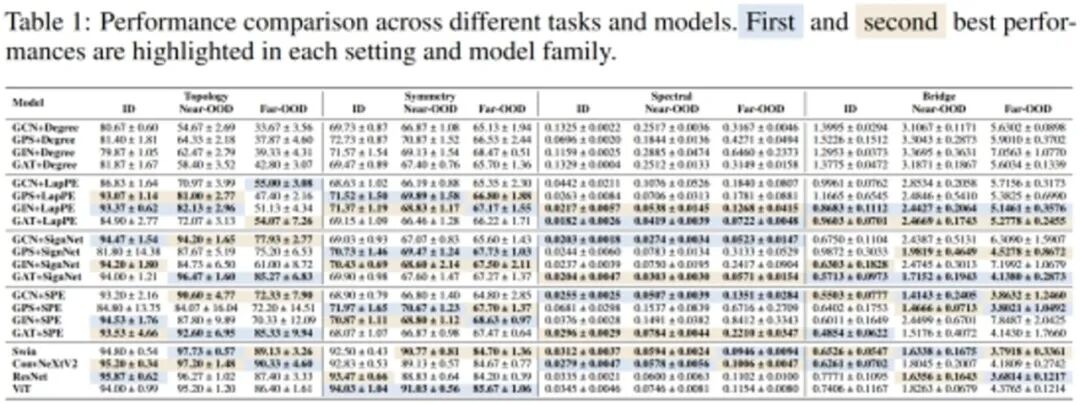
STEP: A Unified Spiking Transformer Evaluation Platform for Fair and Reproducible Benchmarking **作者:**沈思成,赵东城,冯令昊,岳泽阳,李金东,李腾龙,申国斌,曾毅 随着类脑智能的快速发展,脉冲神经网络凭借其稀疏性与事件驱动特性展现出突出的高能效优势。近年来,研究者提出了一系列Spiking Transformer模型。然而,该领域目前仍缺乏统一的实现与评测平台,导致实验结果难以复现,不同模型间的比较亦缺乏公平性。 为此,本文提出跬步(STEP,Spiking Transformer Evaluation Platform),一个面向Spiking Transformer 的统一基准框架。STEP支持分类、分割与检测等多类视觉任务,覆盖静态图像、事件驱动数据与序列数据集。平台采用模块化设计,使研究者能够灵活替换神经元模型、编码方式与注意力机制,并提供一致的训练流程。在CIFAR、ImageNet、ADE20K与COCO等数据集上的系统复现与消融实验表明,现有Spiking Transformer在很大程度上依赖卷积前端,而注意力机制贡献有限;同时,实验结果进一步凸显了神经元模型与编码策略对模型性能的显著影响。与此同时,我们提出统一的能耗分析框架,考虑了之前的框架都没有考虑的访存开销,并发现在此度量下,量化ANN在部分场景中甚至展现出优于脉冲模型的能效表现。综上,STEP的发布不仅为该领域建立了公平、可复现的评测基线,也为未来探索真正的脉冲原生架构奠定了坚实基础。
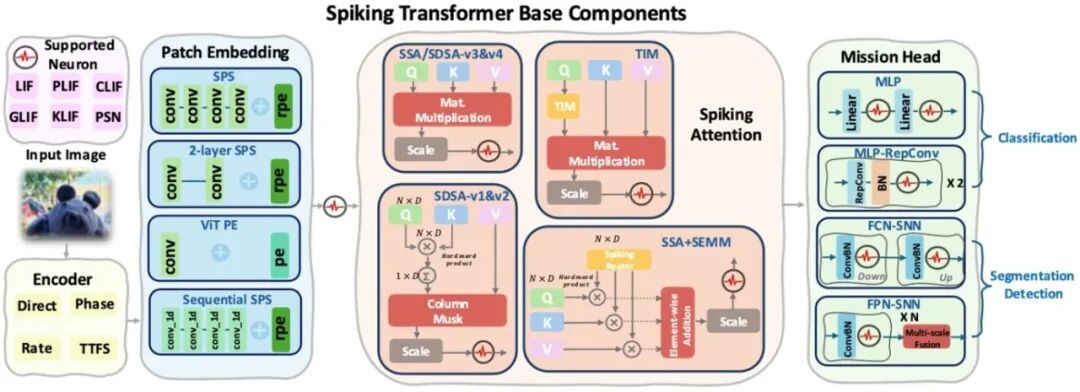
图1. Spiking Transformer基本结构示意图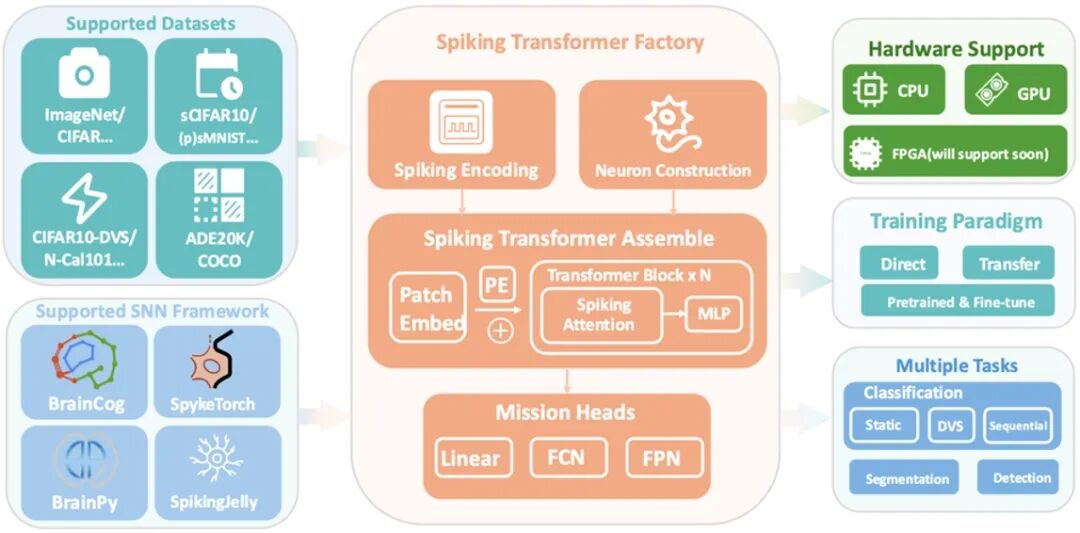
13.** **SOLIDGEO:立体几何中的多模态空间数学推理能力评估
SOLIDGEO: Measuring Multimodal Spatial Math Reasoning in Solid Geometry **作者:**王培杰,杨超,李忠志,殷飞,冉德康,田密,冀志龙,白锦峰,刘成林 几何是数学的一个基础分支,在评估多模态大语言模型 (MLLM) 的推理能力方面发挥着至关重要的作用。然而,现有的多模态数学基准测试主要侧重于平面几何,基本上都忽略了立体几何。立体几何需要空间推理能力,比平面几何更具挑战性。 为了弥补这一关键缺陷,我们推出了SOLIDGEO,这是首个专门用于评估 MLLM立体几何数学推理能力的大规模基准测试。SOLIDGEO包含3,113 个现实世界的 K-12 和竞赛级问题,每个问题都配有视觉上下文,并标注了难度级别和细粒度的立体几何类别。我们的基准测试涵盖了投影、展开、空间测量和空间矢量等广泛的空间推理主题,为评估立体几何提供了严格的测试平台。通过大量的实验,我们观察到 MLLM 在立体几何数学任务中面临着巨大的挑战,其在SOLIDGEO上的性能与人类能力存在显著差距。此外,我们分析了各种模型的性能、推理效率和错误模式,从而更深入地揭示了MLLM的立体几何数学推理能力。我们希望 SOLIDGEO能够推动MLLM迈向更深层次的几何推理和空间智能。
图1.左图为6个MLLM在SOLIDGEO基准上8个立体几何主题的表现;右图为25个 MLLM 的准确率与平均生成长度
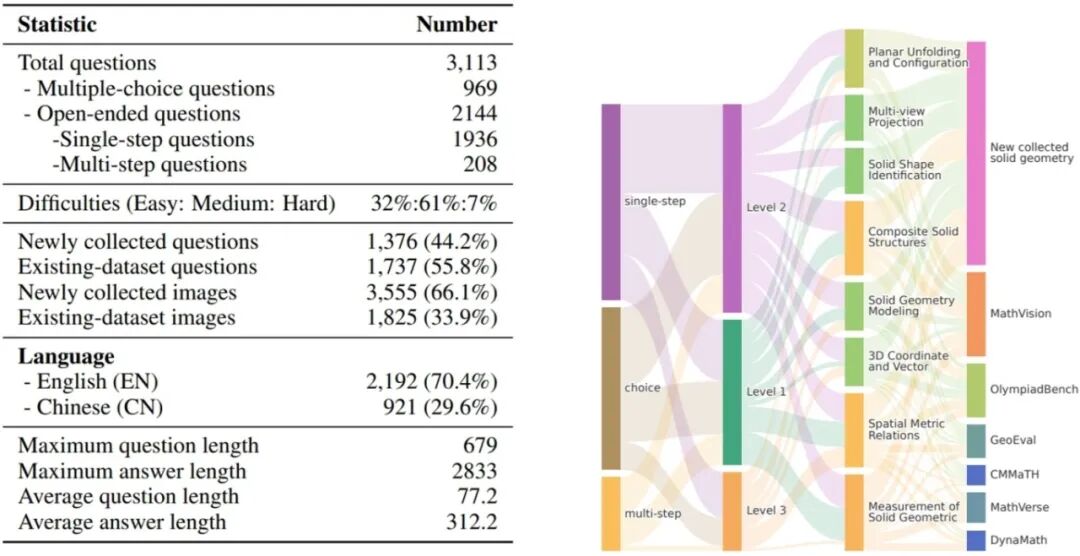
图2. SOLIDGEO关键统计数据与分布
14.** **学习何时思考:多阶段强化学习赋能R1风格大语言模型自适应推理
Learning When to Think: Shaping Adaptive Reasoning in R1-Style Models via Multi-Stage RL **作者:**凃崧峻,林佳豪,张启超,田翔宇,李林静,蓝湘源,赵冬斌 近年来,推理大模型在数学、逻辑等复杂任务中展现出卓越的推理能力。典型的推理模型通过
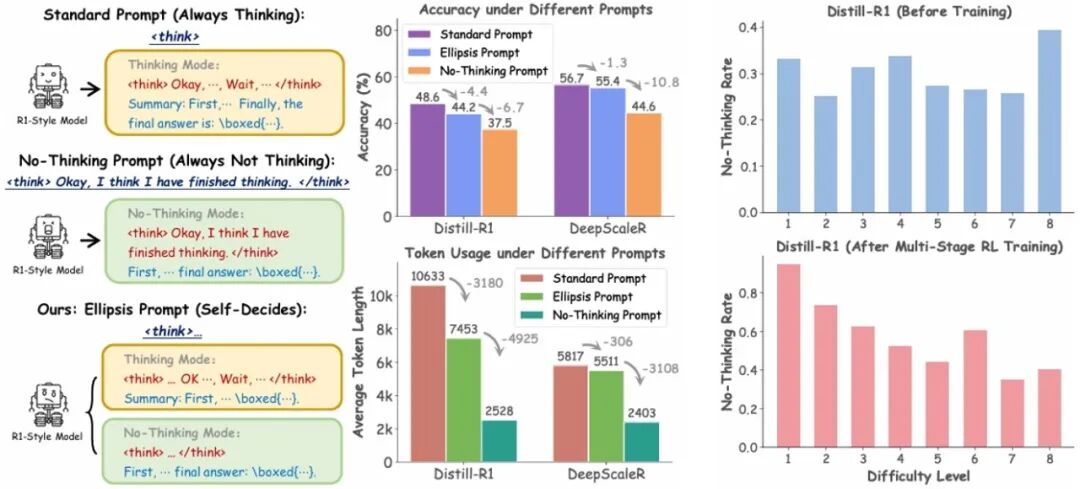
左侧: 标准提示与省略号提示下的准确率和 Token 使用量; 右侧: 按难度划分的无思考行为比例
15.** **均衡策略泛化:一种实现追逃博弈策略跨图零样本泛化的强化学习框架
Equilibrium Policy Generalization: A Reinforcement Learning Framework for Cross-Graph Zero-Shot Generalization in Pursuit-Evasion Games **作者:**陆润宇,张鹏,石若川,朱圆恒,赵冬斌,刘洋,王栋,Cesare Alippi 追逃博弈(PEG)作为机器人与安防领域典型的现实博弈问题,其精确求解需要指数级时间。当博弈底层图结构发生变化时,即便最先进的强化学习方法也需要微调而不能保证实时性。本文提出一种均衡策略泛化(EPG)框架,旨在学习具有跨图零样本性能的通用实时博弈策略。EPG框架同时适用于PEG问题的追捕者与逃逸者双方,且兼容无出口与多出口两种情形,是领域内首次实现跨图博弈策略泛化的一般方法。 EPG框架的核心思想是在不同图结构下对抗各自的均衡对手策略进行强化学习,得到鲁棒的图网络泛化策略。本文首先设计了一种理论高效的动态规划算法作为均衡策略的生成器;为提升对追捕者数量的可扩展性,提出了分组机制与序贯模型以实现联合策略分解。实验表明,结合一种均衡引导机制以及适配跨图追逃策略训练的距离特征,EPG方法能在多种现实图结构下得到理想的零样本性能。对于多出口的追逃博弈,本文零样本泛化的实时追捕策略甚至能够达到或超越当前最优方法的微调策略性能。
图1.均衡策略泛化(EPG)框架的强化学习训练过程
图2.多出口追捕场景下EPG方法的零样本性能与已有方法的微调性能对比
16.基于专家混合世界模型的多智能体多任务学习与规划********
Learning and Planning Multi-Agent Tasks via a MoE-based World Model **作者:**赵子杰,赵中岳,徐凯旋,傅宇千,柴嘉骏,朱圆恒,赵冬斌 多任务多智能体强化学习的目标是训练一个统一模型来完成多种任务。然而,不同任务的最优策略之间显著差异,导致单一模型难以胜任。本文发现,任务间在动力学层面往往存在“有界相似性”。例如开门与关门任务的最优策略截然相反,却具有高度相似的动力学。 基于这一观察,本文提出了一种新的框架M3W(Mixture-of-Experts based Multi-task Multi-Agent World Model)。M3W首次将专家混合结构引入世界模型,而非策略网络。具体而言,框架通过SoftMoE建模多智能体动力学,并利用SparseMoE预测奖励,从而在相似任务间实现知识共享,同时隔离不相似任务,避免梯度冲突。在规划阶段,M3W直接基于世界模型生成的虚拟轨迹进行评估与优化,跳过显式策略网络,从根本上克服了策略中心方法的局限。通过在Bi-DexHands和MA-Mujoco两大基准上的实验验证了M3W的有效性,结果显示其在性能、样本效率与任务适应性方面均显著优于现有方法。本文不仅提升了多任务学习的可解释性,还展示了模块化世界模型在多智能体合作中的潜力。
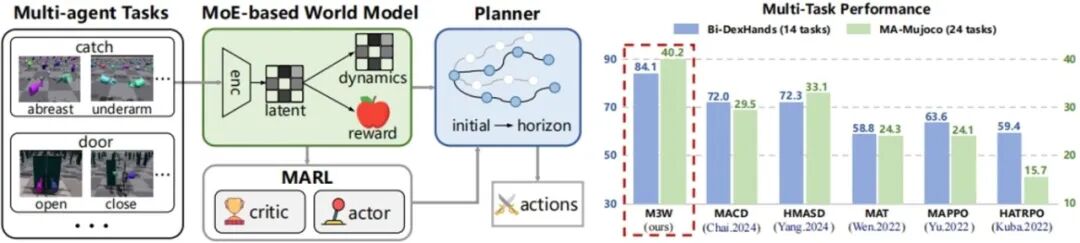
图1.M3W的整体框架(左侧)和性能对比(右侧)
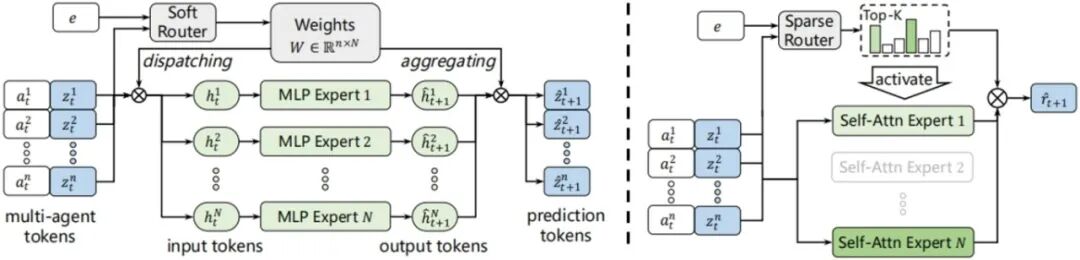
图2.基于SoftMoE的动力学预测器(左侧)和基于SparseMoE的奖励预测器(右侧)
17.** **视频是采样高效的监督器:基于隐表示学习视频的行为克隆
Videos are Sample-Efficient Supervisions: Behavior Cloning from Videos via Latent Representations **作者:**刘鑫,李浩然,赵冬斌 人类仅需少量试错就能从演示视频中提取知识并学习技能。然而,要让智能体复现这一高效的学习过程却面临巨大挑战,这源于视觉输入的复杂性、动作与奖励信号的缺失,以及受限的环境交互次数。 本文提出了一种两阶段的、无监督且样本高效的视频模仿学习框架,BCV-LR。离线阶段,BCV-LR从高维视频输入中提取与动作相关的自监督隐特征,随后优化基于动力学的无监督目标,预测连续帧之间的隐动作。在线阶段,通过收集真实交互数据,将隐动作对齐到真实动作空间,从而作为标签以支持行为克隆。克隆的策略会丰富交互数据,以进一步微调对齐视频隐动作,形成迭代式的高效策略提升。在包括离散与连续控制在内的一系列复杂视觉任务上的实验结果表明,BCV-LR 仅需少量交互就能实现有效的策略模仿,甚至在部分任务中达到专家水平。具体地,在24/28项任务中,BCV-LR的样本效率超过了当前最先进的视频模仿学习基线以及视觉强化学习方法。本文表明:无需依赖任何其他专家监督,仅通过视频即可实现高效视觉策略学习。
BCV-LR方法框架。左半部分为离线预训练阶段,右半部分为在线微调阶段
18.** **DRT-M3D:非增强胸部 CT 上的双侧乳腺病变检测与分类
Dual-Res Tandem Mamba-3D: Bilateral Breast Lesion Detection and Classification on Non-contrast Chest CT **作者:**周嘉恒,方伟,谢鲁源,周岩峰,徐潋滟,许敏丰,杨戈,唐禹行 乳腺癌是全球女性疾病死亡的主要原因之一,早期筛查对于提高生存率至关重要。非增强胸部计算机断层扫描(NCCT)在临床常规检查中应用广泛,且常常包含乳腺区的影像,这为在不额外增加检查成本和辐射暴露的前提下,实现乳腺病变的机会性筛查提供了新的可能。然而乳腺病变在NCCT影像中的特征并不明显,并且如何在NCCT影像中同时实现高质量的病灶检测与癌症分类,也是现有方法面临的重要技术挑战。 针对上述问题,本研究提出了一种创新性的多任务模型框架Dual-Res Tandem Mamba-3D(DRT-M3D)。通过将乳腺病灶分割与癌症分类两项任务分解到不同分辨率的子通路中,DRT-M3D实现了分割与分类任务间的互补学习;同时通过双侧乳腺的串联输入,模型能够联合建模并比较两侧乳腺的影像特征,从而提升病变检出能力与分类准确性。在多中心NCCT数据集上的实验结果显示,DRT-M3D在各项任务上均显著优于现有方法,具有良好的泛化性与鲁棒性,充分展示了其在机会性乳腺癌分析方面的应用潜力。
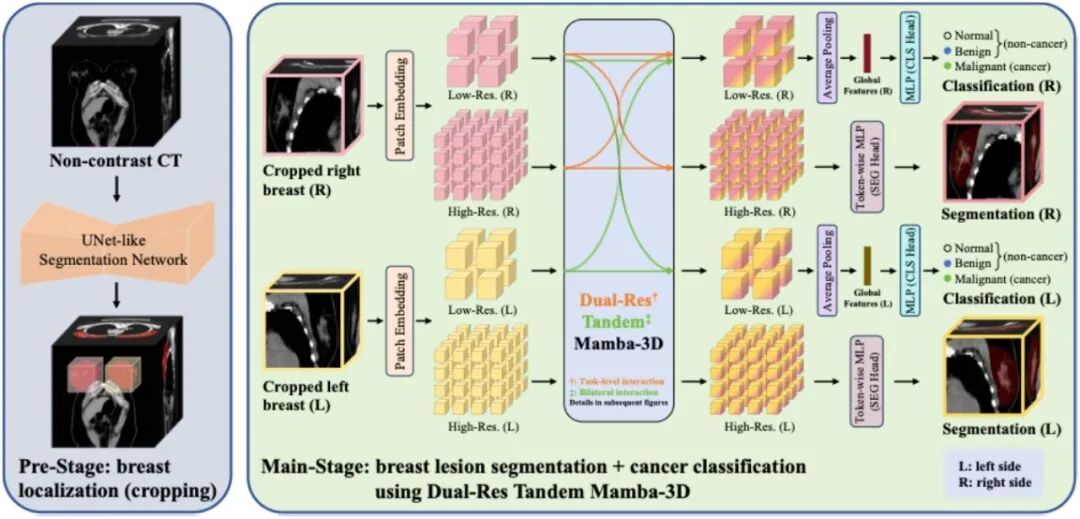
图1.本研究提出的机会性乳腺癌双侧分析方法的整体流程
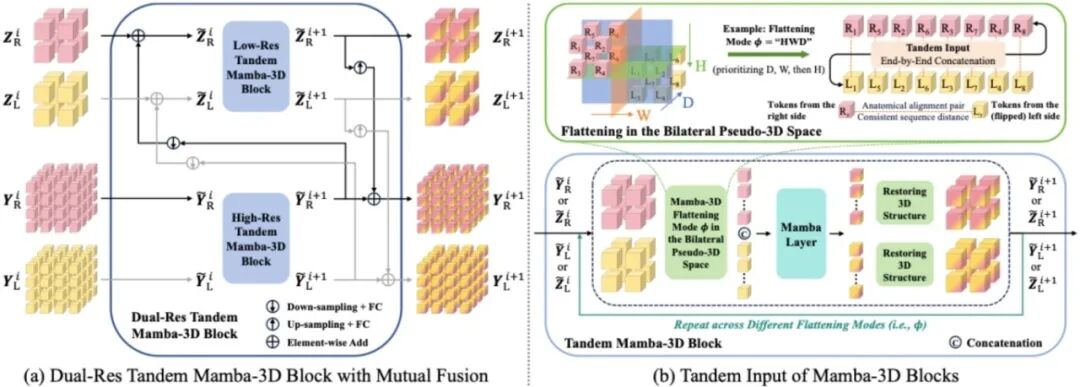
图2.双分辨率串联Mamba-3D块结构
19.** **KTAE:数学推理中关键token优势估计的无模型算法
KTAE: A Model-Free Algorithm to Key-Tokens Advantage Estimation in Mathematical Reasoning **作者:**孙为,杨文,简璞,杜倩龙,崔福伟,任烁,张家俊 近年来的研究表明,将强化学习与基于规则的奖励相结合,即使在没有监督微调(SFT)的情况下,也能显著提升大语言模型(LLMs)的推理能力。然而,现有的强化学习算法,如 GRPO 及其变体 DAPO,在计算优势函数时存在粒度过粗的问题。具体而言,它们采用基于整段生成的优势估计方式,使得序列中的每个 token 被赋予相同的优势值,从而无法刻画各个 token 对最终结果的具体贡献。 为解决这一局限,我们提出了一种新算法——关键 Token 优势估计(KTAE, Key-token Advantage Estimation)。该方法无需额外引入模型,就能够实现更细粒度的 token 级优势估计。KTAE 基于采样生成的正确性,并通过统计分析量化序列中各个 token 对最终结果的重要性。随后,将这一 token 级的重要性与 rollout 级优势相结合,从而得到更精细化的 token 级优势估计。 实验结果表明,采用 GRPO+KTAE 与 DAPO+KTAE 训练的模型在五个数学推理基准测试中均优于现有基线方法。值得注意的是,这些模型不仅在准确率上更高,而且生成的回答更简洁,甚至在使用相同基座模型的条件下,超越了 R1-Distill-Qwen-1.5B。
图1. KTAE 是一种即插即用的方法,无需引入任何额外的模型。它为现有的强化学习算法(例如 GRPO 及其变体)提供token级的优势估计。“GRPO+KTAE”和“DAPO+KTAE”分别表示 GRPO 和 DAPO 与 KTAE 的组合,两者均基于 Qwen2.5-Math-7B 模型进行了强化学习训练。
图2. KTAE 算法概要。该算法根据采样 rollout 的正确性构建一个列联表,然后计算 token 级优势并将其添加到 GRPO 的 rollout 级优势中。

