摘要—视觉—语言模型(Vision-Language Models, VLMs)在广泛任务中展现出卓越的泛化能力。然而,当直接应用于特定下游场景且未经过任务特定的适配时,其性能往往并不理想。为了在保持数据高效性的同时提升其实用性,近年来的研究日益聚焦于不依赖标注数据的无监督适配方法。尽管这一方向的关注度不断上升,但仍缺乏一个面向任务的、专门针对无监督 VLM 适配的统一综述。为弥补这一空白,本文对该领域进行了全面且结构化的梳理。我们提出了一种基于无标注视觉数据可得性及其性质的分类方法,将现有方法划分为四种核心范式:无数据迁移(Data-Free Transfer,无数据)、无监督领域迁移(Unsupervised Domain Transfer,充足数据)、情景式测试时适配(Episodic Test-Time Adaptation,批量数据)和在线测试时适配(Online Test-Time Adaptation,流式数据)。在这一框架下,我们分析了各范式对应的核心方法与适配策略,旨在构建对该领域的系统化理解。此外,我们还回顾了多种应用场景下的代表性基准,并指出了开放挑战与未来研究的潜在方向。相关文献的持续更新仓库可访问:https://github.com/tim-learn/Awesome-LabelFree-VLMs。 关键词—无监督学习,测试时适配,多模态学习,视觉—语言模型。 I. 引言
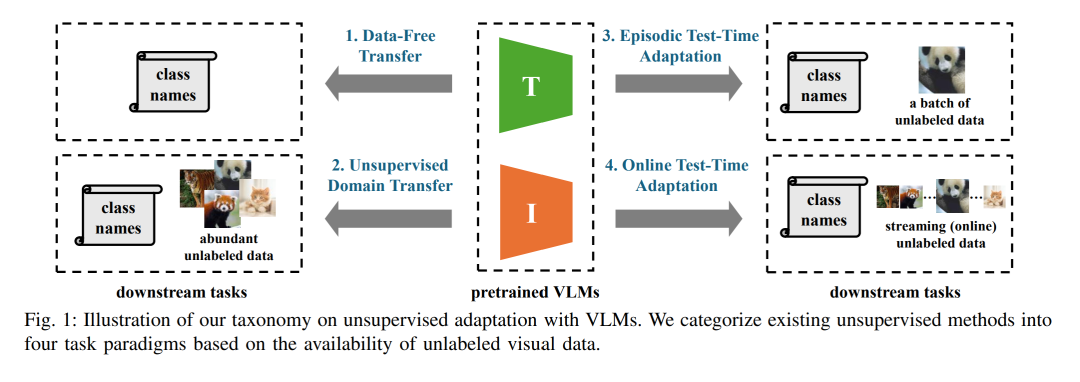
视觉—语言模型(Vision-Language Models, VLMs),如 CLIP [1]、ALIGN [2]、Flamingo [3] 和 LLaVA [4],凭借强大的跨模态推理能力,已在学术界和工业界引起了广泛关注。这类模型通过大规模数据集 [5] 学习图像—文本的联合表示,并在多种任务中展现出令人印象深刻的零样本(zero-shot)性能与泛化能力。VLMs 已成功应用于多个领域,包括自动驾驶 [6]、机器人技术 [7]、异常检测 [8] 以及跨模态检索 [9]。 然而,由于预训练阶段无法覆盖下游任务与环境的全部多样性,将 VLMs 适配于特定应用仍是一项核心挑战。早期的研究主要依赖有监督微调 [10]–[13],利用带标注样本挖掘更多知识。尽管该方法在性能上有效,但依然面临高标注成本,以及在训练与测试数据存在分布偏移(distribution shift)[14] 时的性能下降问题。为应对这些局限,越来越多的研究开始探索无监督适配技术 [15]–[20]。这些方法——通常被称为零样本推理 [21]–[23]、测试时方法(test-time methods)[18], [24], [25],或无监督调优 [17], [26], [27]——旨在无需昂贵标注即可提升 VLMs 在下游任务中的表现。实践表明,这类方法在图像分类 [15], [17], [18]、图像分割 [16], [28], [29]、医学影像诊断 [30], [31] 以及动作识别 [32], [33] 等任务中均取得了显著成效。 鉴于该研究领域的快速发展,本文旨在对现有 VLM 无监督适配方法进行全面且结构化的综述。据我们所知,这是首个围绕无标注视觉数据可得性提出分类体系的工作——这一因素在实际部署中至关重要,却往往被忽视。如图 1 所示,我们将现有方法划分为四种范式: 1. 无数据迁移(Data-Free Transfer)[15], [16], [21]:仅利用文本类别名称来适配模型; 1. 无监督领域迁移(Unsupervised Domain Transfer)[17], [34], [35]:利用来自下游任务的充足无标注数据; 1. 情景式测试时适配(Episodic Test-Time Adaptation)[18], [24], [36]:针对一批测试样本进行适配; 1. 在线测试时适配(Online Test-Time Adaptation)[19], [23], [25]:应对流式到达的测试数据。
这一分类体系为理解 VLM 无监督适配的研究版图提供了系统化框架,有助于实践者选择合适的技术路径,同时也有助于未来在同一范式下进行公平比较。 本文的组织结构如图 2 所示:第 II 节概述了与 VLM 无监督学习相关的研究主题;第 III 节介绍了 VLM 的零样本推理,并提出基于无标注视觉数据可得性的分类体系;第 IV–VII 节为本文核心内容,分别分析无数据迁移、无监督领域迁移、情景式测试时适配以及在线测试时适配中的现有方法;第 VIII 节探讨无监督技术在多种应用场景中的实践及相关基准,扩展对其实际意义和应用价值的认识;第 IX 节总结该领域的新兴趋势,并指出可能激发未来研究的关键科学问题。 与已有综述的对比。 近年来,一些综述性工作 [37]–[40] 涉及了无监督适配与 VLM 微调的不同方面。现有研究 [40]–[42] 多聚焦于单模态模型迁移,虽然对该领域进行了深入分析,但对 VLM 的覆盖较为有限。较早的工作 [37] 讨论了 VLM 的预训练阶段,并简要分析了其在视觉任务上的微调方法;另一篇综述 [38] 涉及多模态模型的适配与泛化,但粒度较为粗略;近期工作 [39] 从参数空间视角审视 VLM 下游任务的泛化,并回顾了相关方法。尽管这些综述提供了有价值的见解,但本文首次基于无标注视觉数据可得性提出了分类体系,并在每个范式下深入分析前沿技术,我们认为这是对该领域的一个新颖且关键的补充,尤其对 VLM 的实际部署具有重要意义。