

大型语言模型(LLMs)的出现产生了变革性的影响。然而,像ChatGPT这样的LLMs可能被用来生成错误信息,这对在线安全和公众信任构成了严重的担忧。一个基本的研究问题是:LLM生成的错误信息会比人类编写的错误信息造成更大的伤害吗?我们提议从检测难度的角度来处理这个问题。我们首先构建一个LLM生成错误信息的分类体系。然后,我们对用LLMs生成错误信息的潜在现实世界方法进行分类和验证。接着,通过广泛的实证调查,我们发现与具有相同语义的人类编写的错误信息相比,LLM生成的错误信息对于人类和检测器来说更难以检测,这表明它可能具有更具欺骗性的风格,并可能造成更大的伤害。我们还讨论了我们的发现对于在LLMs时代对抗错误信息的影响以及相应的对策。
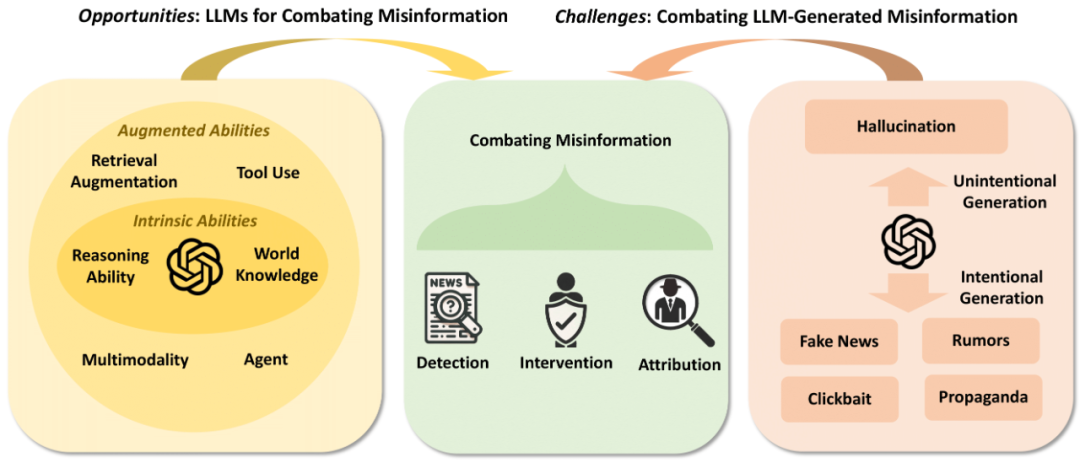
大型语言模型(LLMs)代表了人工智能的重大进步(Zhao et al., 2023)。特别是,作为一个典型的LLM,ChatGPT在多种任务中展示了其强大的能力,比如机器翻译(Lai et al., 2023)、逻辑推理(Liu et al., 2023)、概要总结(Zhang et al., 2023a)和复杂问题解答(Tan et al., 2023)。然而,由于像ChatGPT这样的LLMs能够生成类似人类的内容,它们对在线安全和公众信任构成了严重威胁,即LLMs可能被用于生成错误信息。因此,一个新兴的基础研究问题如下:

诚然,由大型语言模型(LLM)产生的错误信息之害是一个多方面、跨学科的问题。在本文中,我们提议从计算角度来探讨这一问题。具体来说,我们旨在研究与人类编写的错误信息相比,由LLM生成的错误信息的检测难度。错误信息检测的任务是确定给定文本的真实性,判断其为“事实”或“非事实”。如果显示由LLM生成的错误信息比具有相同语义的人类编写的错误信息更难以被人类和检测器发现,则我们可以获得经验证据,表明由LLM生成的错误信息可能具有更具欺骗性的风格,并在现实世界中造成更大的伤害。为此,我们的目标可以分解为三个具体的研究问题。 第一个问题是:**LLM如何被用来生成错误信息?**人类编写的和LLM生成的错误信息的典型检测流程如图1所示。通常,由LLM生成的错误信息可以是无意的或有意的。我们将从正常用户生成的结果中的幻觉视为无意的情形,而恶意用户故意提示LLM生成错误信息则视为有意的情形。我们首先建立一个由LLM生成的错误信息的分类,并系统地分类潜在的LLM在现实世界中生成错误信息的方法。然后,在经过实证验证后,我们的第一个核心发现是:LLM可以被指示生成不同类型、领域和错误的错误信息。
接下来,第二个问题是:**人类能否检测出由LLM生成的错误信息?**我们利用相同的人类评估者组来评估由LLM生成和人类编写的错误信息数据的检测难度。同样地,第三个问题是:**检测器能否检测出由LLM生成的错误信息?**我们在零样本(zero-shot)设置中评估由LLM生成和人类编写的错误信息数据的检测难度,以更好地反映LLM时代的现实世界情景(详见第6节)。
对于第二和第三个问题,通过广泛调查不同的LLM错误信息生成器(ChatGPT、Llama2-7b(或13b、70b)、Vicuna-7b(或13b、33b))和生成策略(改写生成、重写生成和开放式生成),我们的发现是:与具有相同语义的人类编写的错误信息相比,由LLM生成的错误信息对于人类和检测器来说可能更难以检测。直接的含义是,由LLM生成的错误信息可以具有更多的欺骗性风格,并可能从计算角度造成更大的伤害。总体而言,本文的贡献包括:
我们按类型、领域、来源、意图和错误来建立分类,系统地表征由LLM生成的错误信息作为一个新兴且关键的研究主题。
我们首次尝试分类并验证潜在的LLM在现实世界中生成错误信息的方法,包括幻觉生成、任意错误信息生成和可控错误信息生成方法。
我们发现,通过广泛调查,与具有相同语义的人类编写的错误信息相比,LLM生成的错误信息对于人类和检测器来说更难以检测,这为表明LLM生成的错误信息可能具有更多的欺骗性风格,并可能造成更大伤害提供了充分的经验证据。
我们讨论了错误信息检测器面临的新兴挑战(第6节)、我们发现对于LLM时代对抗错误信息的重要影响(第7节),以及通过LLM的整个生命周期对抗由LLM生成的错误信息的对策(第8节)。