
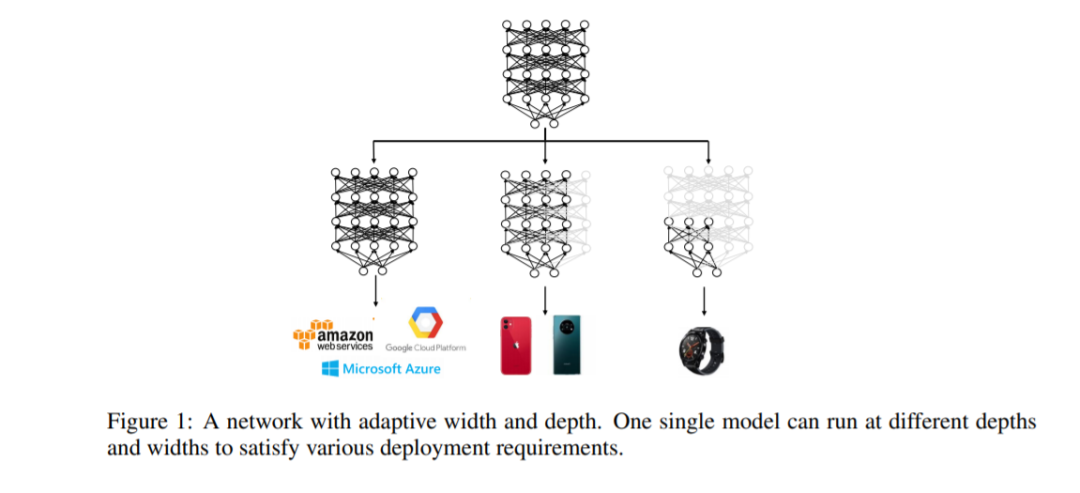
像BERT和RoBERTa这样的预训练语言模型,尽管在许多自然语言处理任务中功能强大,但在计算和内存方面都很昂贵。为了缓解这个问题,一种方法是在部署之前对特定任务进行压缩。然而,最近的BERT压缩工作通常将大的BERT模型压缩到一个固定的更小的尺寸,并不能完全满足不同硬件性能的不同边缘器件的要求。在本文中,我们提出了一种新的动态BERT模型(简称DynaBERT),它可以在自适应的宽度和深度上运行。DynaBERT的训练过程包括首先训练一个宽度自适应的BERT,然后通过从全尺寸的模型中提取知识到小的子网络中,允许自适应的宽度和深度。网络重布线也被用来让更多的子网络共享更重要的注意力头部和神经元。在各种效率约束下的综合实验表明,我们提出的动态BERT(或RoBERTa)在其最大尺寸下的性能与BERT(或RoBERTa)相当,而在较小的宽度和深度下,动态BERT(或RoBERTa)的性能始终优于现有的BERT压缩方法。
成为VIP会员查看完整内容
相关内容

专知会员服务
21+阅读 · 2020年4月30日
专知会员服务
64+阅读 · 2020年4月28日
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
相关VIP内容
专知会员服务
21+阅读 · 2020年4月30日
专知会员服务
64+阅读 · 2020年4月28日
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
相关资讯
相关论文