
大语言模型(LLMs)的后训练(Post-training)对于释放其任务泛化潜能和领域特定能力至关重要。然而,现有的大语言模型后训练范式面临着显著的数据挑战,包括人工标注成本高昂以及数据规模扩增带来的边际收益递减等问题。因此,实现数据高效的后训练已成为一个关键的研究问题。 本文从数据中心(data-centric)视角出发,首次系统性地综述了数据高效大语言模型后训练的研究进展。我们提出了一种关于数据高效后训练方法的系统化分类体系,涵盖以下几个核心方向: * 数据选择(Data Selection), * 数据质量提升(Data Quality Enhancement), * 合成数据生成(Synthetic Data Generation), * 数据蒸馏与压缩(Data Distillation and Compression), * 以及自演化数据生态系统(Self-evolving Data Ecosystems)。
我们对每一类方法中的代表性工作进行了总结,并梳理了未来的研究方向。通过对数据高效后训练所面临挑战的分析,本文指出了当前存在的开放性问题,并提出了若干潜在的研究路径。我们希望本研究能够激发学界与业界进一步探索,充分挖掘大规模模型训练中数据利用的潜能。
1 引言
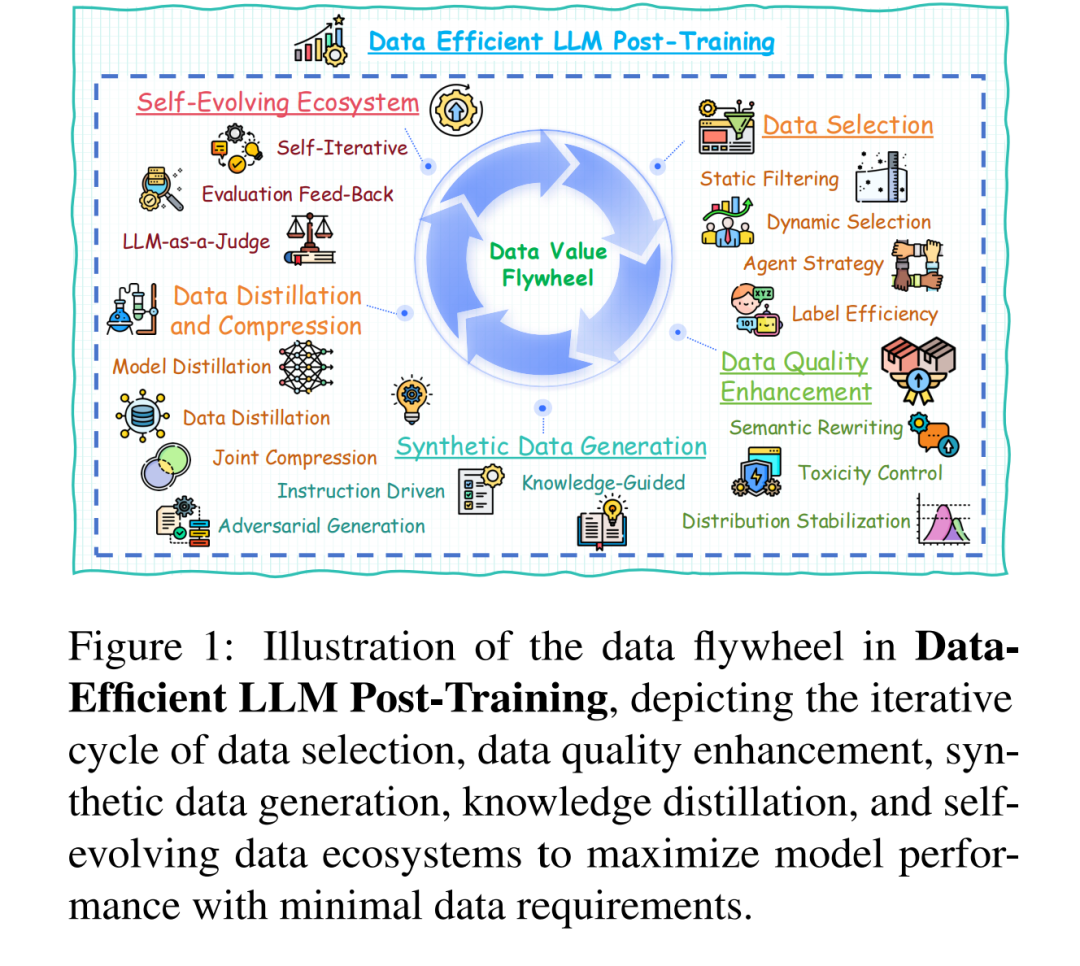
大语言模型(Large Language Models, LLMs)的后训练(post-training)已成为释放其领域自适应能力与任务泛化潜能的关键阶段(Luo et al., 2025b)。这一阶段显著提升了模型在长上下文推理(Zelikman et al., 2022; Yuan et al., 2024c)、人类对齐(human alignment)(Rafailov et al., 2024)、指令微调(instruction tuning)(Zhang et al., 2023b)以及领域特定自适应(domain-specific adaptation)(Cheng et al., 2024)等方面的能力。 在大语言模型的后训练阶段,数据是驱动模型进化的核心力量。然而,当前的后训练范式正面临严重的数据困境: 一方面,高质量数据的人工标注成本急剧上升;另一方面,单纯扩大数据规模带来的性能提升呈现明显的边际递减效应。此外,静态数据集天然限制了模型对动态现实知识的持续适应能力。这种模型性能与数据规模之间的线性依赖关系,从根本上源于传统后训练范式中数据利用效率的低下。 近期的 DeepSeek-R1(Guo et al., 2025)取得的成功进一步印证了这一点——该模型通过引入强化学习实现了数据高效的后训练,显著提升了模型性能,充分展示了数据高效方法的有效性与必要性。 为此,本文构建了首个关于数据高效大语言模型训练的系统性综述,旨在通过一个统一化与体系化的框架整合这一领域碎片化的研究成果。我们的研究揭示,突破效率瓶颈的关键并非单纯扩大数据规模,而在于贯穿数据生命周期的价值提取机制。 学术界已探索出多种策略来充分挖掘后训练阶段的数据潜能(Jeong et al., 2024; Wang et al., 2024a; Pan et al., 2024b)。虽然这些方法在提升数据效率方面取得了显著进展,但目前仍缺乏系统性的综述与统一视角。 本文从**数据中心视角(data-centric perspective)出发,全面综述了数据高效大语言模型后训练的研究进展。我们提出了一个名为“数据价值飞轮(data value flywheel)”**的概念(如图1所示),该框架由以下五个关键组成部分构成: 1. 数据选择(Data Selection), 1. 数据质量提升(Data Quality Enhancement), 1. 合成数据生成(Synthetic Data Generation), 1. 数据蒸馏与压缩(Data Distillation and Compression), 1. 自演化数据生态系统(Self-evolving Data Ecosystems)。
基于此框架,我们提出了一个系统化的分类体系,总结了各类代表性方法,并指出了未来值得探索的研究方向。希望本综述既能为领域初学者提供清晰的学习路线,也能为研究者和实践者提供未来进展的参考指南。 与现有综述的区别。 尽管已有若干工作探讨了LLM后训练的某些方面,如数据选择(Wang et al., 2024b)、合成数据生成(Long et al., 2024; Tan et al., 2024)、模型自反馈(self-feedback)(Liang et al., 2024a; Pan et al., 2023)、自演化机制(self-evolution)(Tao et al., 2024)、可信性(trustworthiness)(Liu et al., 2023)以及时间效率(time-efficiency)(Wan et al., 2023),但这些研究往往聚焦于单一维度,缺乏整体化与统一的数据效率视角。 本综述填补了这一空白,从数据效率的整体框架出发,对各类方法进行了系统性梳理与比较,为最大化数据价值提取提供了关键洞见。
