
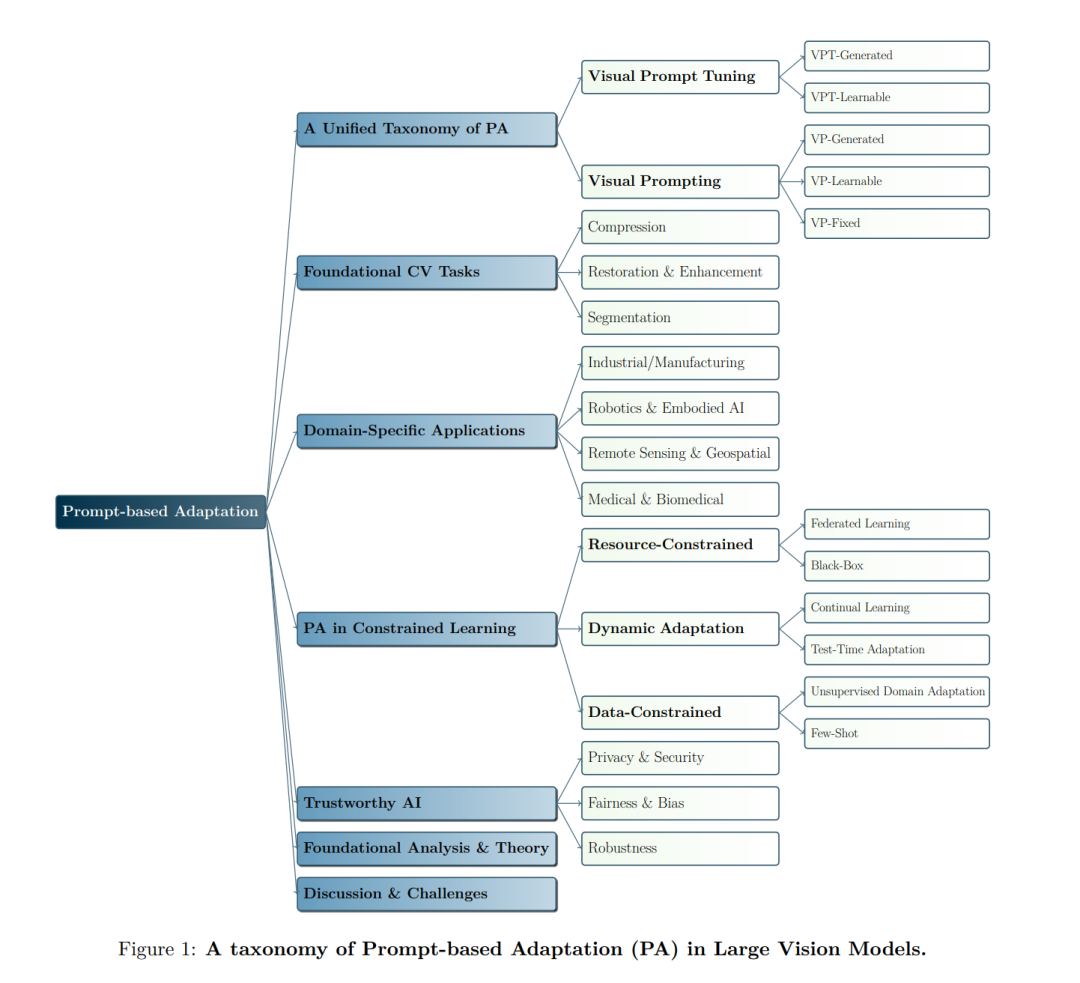
在计算机视觉领域,视觉提示(Visual Prompting,VP)和视觉提示调优(Visual Prompt Tuning,VPT)最近作为一种轻量且有效的替代方法,成为在“预训练-再训练”(pretrain-then-finetune)范式下,适配大规模视觉模型的手段。然而,尽管取得了快速进展,这些技术的概念边界仍然模糊,因为在当前的研究中,VP和VPT经常被交替使用,反映出这两种技术及其各自应用之间缺乏系统的区分。在本综述中,我们从基础原理重新审视了VP和VPT的设计,并将其在统一的框架下进行概念化,命名为基于提示的适应(Prompt-based Adaptation,PA)。我们提供了一种分类法,将现有方法分为可学习提示、生成式提示和非可学习提示,并进一步按注入粒度(像素级和标记级)进行组织。除了核心方法论外,我们还考察了PA在各个领域的集成,包括医学影像、3D点云和视觉语言任务,以及它在测试时适应和可信AI中的作用。我们还总结了当前的基准测试,并识别出主要的挑战和未来的研究方向。据我们所知,本综述是第一篇全面回顾PA方法及应用的综述,聚焦于其独特特性。我们的综述旨在为所有领域的研究人员和实践者提供一条清晰的路线图,以理解和探索PA相关研究的不断发展。在此,我们鼓励读者访问https://github.com/yunbeizhang/Awesome-Visual-Prompt-Tuning,以获取完整的基于提示的适应方法列表。 1 引言 大规模视觉模型,例如视觉变换器(Vision Transformer,ViT)(Dosovitskiy 等,2021)和 Swin 变换器(Liu 等,2021),已经从根本上改变了计算机视觉。这些模型通常在大量数据集(例如 ImageNet-21k(Russakovsky 等,2015))上进行预训练,以获取可转移的表征,然后可以针对特定的下游任务(例如 FGVC(Jia 等,2022),VTAB-1k(Zhai 等,2019))进行微调。这种方法通常被称为“预训练-再训练”(pretrain-then-finetune)范式,可以显著减少对标注数据的依赖(Han 等,2024)。随着这些模型的规模不断增长(Han 等,2023),传统的全量微调(FT)方法,更新所有参数,在计算和存储上变得越来越昂贵,并且可能会侵蚀有价值的预训练知识(Han 等,2024)。对此,一些参数高效微调(PEFT)方法应运而生,旨在通过仅调整少量参数而保持其余部分冻结来对模型进行微调。在这些方法中,基于提示的适应(Prompt-based Adaptation,PA)已经成为一种特别突出且有效的技术(Jia 等,2022)。 在本综述中,我们提供了对最近的 PA 算法及其实际实现的系统回顾和分类。与现有的综述不同,后者主要集中在多模态或视觉-语言设置上,我们的工作专注于视觉模型中的 PA。为了理清当前研究社区中 PA 定义的混乱,本综述的主要贡献是建立了第一个系统化和统一的 PA 概述,专门讨论大规模视觉模型中的 PA。我们提出了一个全面的分类法,首先将大量与提示相关的研究归纳到一个统一的范畴内,然后根据不同的算法设计和用途进行详细分类。 我们的工作结构如下:在第2节中,我们首先定义了 PA 的总体学科,即在不同位置设计输入以微调模型行为的过程。在这个领域中,我们区分了视觉领域中的两个核心范式:❶ 视觉提示(Visual Prompting,VP)和 ❷ 视觉提示调优(Visual Prompt Tuning,VPT)。在第2.2-2.3节中,我们分别介绍了 VP 和 VPT 的算法基础,突出了它们在实现参数效率方面相关但不同的观点。这个分类是通过提示的几何位置来确定的,区分了修改模型输入的提示和在层之前内部集成的提示。在第2.4节中,我们讨论了 PT 和 VPT 所关注的效率范围。在第3节中,我们介绍了 PA 在基础计算机视觉任务中的应用,如分割、恢复和增强、以及压缩。在第4节中,我们探讨了 PA 在高级机器学习问题和各种特定领域背景中的扩展应用,如医学影像和机器人学。在第5节中,我们的综述表明,PA 在各种场景下展现了有效性,且具有可选约束条件。在第6节中,我们讨论了 PA 在可信性方面,特别是将其分类为鲁棒性、公平性和偏见缓解以及隐私和安全。在第7节中,我们深入探讨了 PA 的基础分析和理论基础。最后,在第8节中,我们讨论了关键挑战,并识别了 PA 的未来发展方向。讨论包括 PA 社区中仍需解决的紧迫问题,包括安全性考虑、训练和推理延迟、稳定性以及实际部署的障碍。鉴于 PA 已经在现实场景中得到了应用,这些讨论对于指导未来的研究尤其有价值。
相关工作 现有的与 PA 相关的综述聚焦于有限的范围,因为它们主要集中在多模态或视觉-语言设置上。例如,Wu 等(2024d)集中讨论了 MLLM 中的视觉提示,围绕视觉指令、提示生成和组合推理进行组织,但没有涵盖视觉编码器中的内部像素/标记注入或参数高效调优。(Gu 等,2023)对视觉-语言基础模型(例如 CLIP/Flamingo/Stable Diffusion)中的提示工程进行了系统回顾,强调了文本侧的提示和 VL 流程,而不是视觉骨干中的 PA 机制。(Lei 等,2024)从 AIGC 视角审视计算机视觉中的提示学习,基于 VLMs 和生成模型,但没有按照注入粒度或约束范式进行方法统一。模型重编程:资源高效的跨域机器学习(Chen,2022)通过将像素空间转换框架为可学习的输入重编程层,为跨域迁移提供了 VP 的早期理论基础,为后来的参数高效提示方法提供了灵感。最近,(Ye 等,2025)将讨论扩展到大规模视觉和多模态模型,追溯了 VP 技术从像素级操作到基础层级适应的发展。与此相对,鉴于文本侧和视觉侧提示相关尝试的明显差异,我们专注于视觉模型中的 PA,提出了一个统一的分类法,定义并解开了之前模糊的 PA 定义。我们进一步按生成机制(即可学习/生成式/非可学习)和注入粒度(即像素级与标记级)对方法进行分类。超越方法论,我们系统化了约束学习范式(即少/零-shot、TTA、持续、黑箱、前向仅、联邦),整合了领域应用(即医学、遥感、机器人、工业),并添加了基础分析(即行为证据和效率/理论),提供了前所未有的部署导向指南,这是之前综述未涉及的内容。