
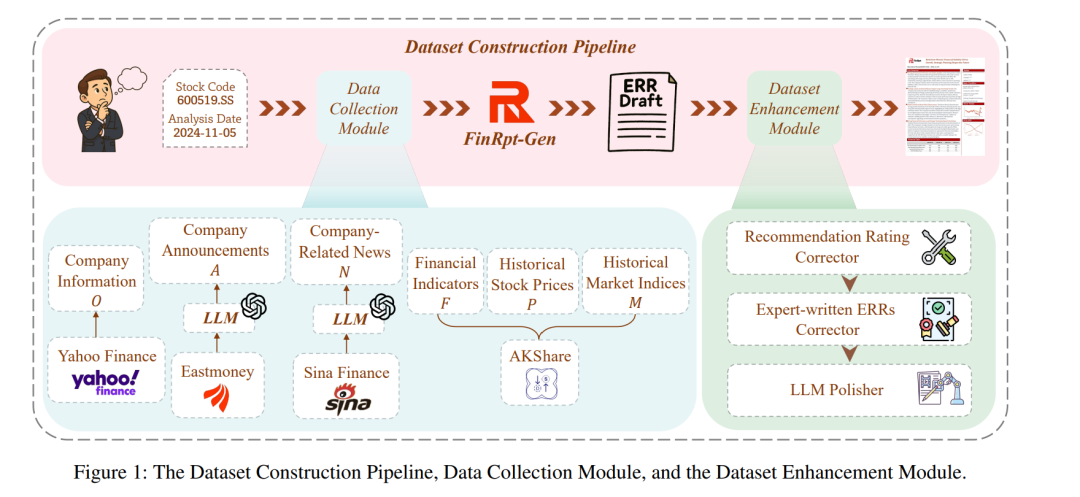
虽然大语言模型(LLMs)在股票预测和金融问答等任务中已取得显著成功,但其在全自动化证券研究报告(Equity Research Report, ERR)生成方面的应用仍属未被探索的领域。本文首次系统性地定义了证券研究报告生成任务。为解决数据稀缺与缺乏评测指标的问题,我们提出了一个面向ERR生成的开源评测基准——FinRpt。 我们构建了一个数据集生成管线,整合了七种金融数据类型,能够自动化地生成高质量ERR数据集,可用于模型训练与评测。此外,我们设计了一个涵盖11项指标的综合评测体系,用于对生成报告的质量进行多维度评估。 同时,我们提出了一个专为该任务设计的多智能体框架——FinRpt-Gen,并基于所提出的数据集,利用监督微调(Supervised Fine-Tuning, SFT)与强化学习(Reinforcement Learning, RL)训练了多个基于大语言模型的智能体。实验结果表明,FinRpt基准的数据质量与评测指标具有较高有效性,而FinRpt-Gen在生成任务中表现出强劲的性能,展示了其在推动证券研究报告生成领域创新方面的潜力。所有代码与数据集均已公开发布。
成为VIP会员查看完整内容

