摘要——人工智能(AI)的快速发展显著扩展了其在各个领域的能力。然而,这也带来了复杂的技术漏洞,例如算法偏见与对抗脆弱性,它们可能引发重大社会风险,包括虚假信息传播、不平等、计算机安全问题、现实世界中的事故,以及公众信任度下降。这些挑战凸显了 AI 治理的紧迫性,以指导 AI 技术的研发与部署。为满足这一需求,我们提出了一个同时整合技术与社会维度的综合 AI 治理框架。具体而言,我们将治理划分为三个相互关联的方面:内生安全(内部系统可靠性)、衍生安全(外部现实危害)和社会伦理(价值对齐与问责制)。我们的独特之处在于,将技术方法、新兴评测基准和政策视角相结合,构建了一个能够主动促进透明性、问责性与公众信任的治理框架。通过对 300 多篇参考文献的系统性回顾,我们识别了三大关键系统性挑战:(1) 泛化差距——现有防御措施难以适应不断演变的威胁;(2) 评测协议不足——未能充分反映真实部署风险;(3) 监管格局碎片化——导致监督与执法的不一致。我们将这些失败归因于当前实践中的根本性错位——治理被视为事后补充,而非基础性设计原则。由此,现有工作往往呈现被动且零散的特征,难以应对技术可靠性与社会信任之间本质上的相互关联性。对此,我们的研究提供了全面的格局分析,并提出了一个融合技术严谨性与社会责任的综合研究议程。该框架为研究人员、工程师与政策制定者提供了可操作的洞见,用于设计既具备性能稳健性,又符合伦理要求并赢得公众信任的 AI 系统。代码仓库可访问:https://github.com/ZTianle/Awesome-AI-SG。 关键词——AI 治理,内生安全,衍生安全,社会伦理,负责任的人工智能
1 引言
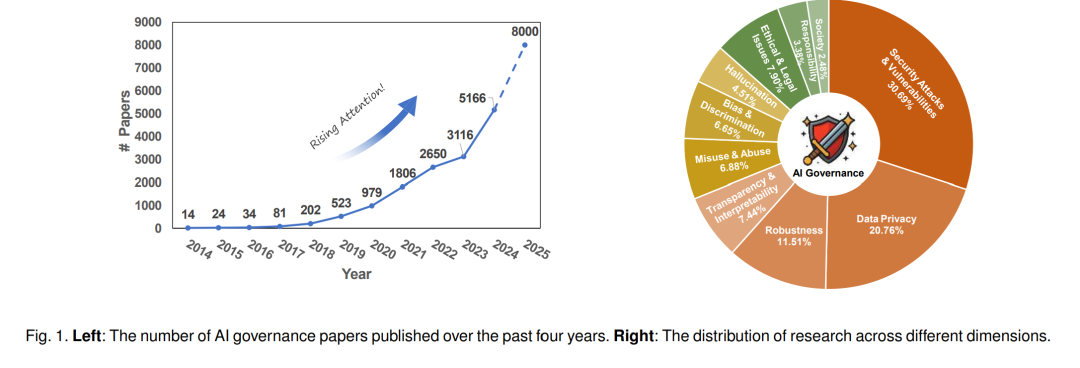
人工智能(AI)的快速发展,尤其是大型语言模型(Large Language Models, LLMs)的出现,正在推动科学 [1]、工业 [2] 和社会 [3] 发生深刻变革。这些模型如今已支持从教育、医疗到法律与公共服务等广泛的应用场景,并在推理 [4]、内容生成 [5] 和决策支持 [6] 等方面展现出前所未有的能力。 然而,伴随这些进步而来的,是一系列与传统软件系统根本不同的新型安全与可靠性挑战。这些挑战包括对抗性脆弱性 [7]、幻觉问题 [8] 以及输出偏差 [9] 等,而这些问题可能被恶意利用并造成严重后果。例如,LLM 可能通过提示注入(prompt injection)被操纵以绕过内容过滤,从而生成有害或非法的建议 [10]。由生成模型驱动的深度伪造(Deepfake)技术 [11] 可能被用于虚假信息传播或非自愿图像生成,侵蚀公众信任与隐私。在医疗场景中,错误的 AI 生成诊断甚至可能导致错误的临床决策,从而危及生命 [12]。这些案例凸显了一个重要事实:AI 系统带来的风险已不再是理论假设——它们正在大规模地影响个人、社区和机构。 针对这些风险,“AI 治理”概念应运而生,作为一个多学科框架,旨在确保 AI 系统不仅在技术上稳健可靠,而且在伦理上对齐、法律上合规,并对社会有益 [13]。AI 治理涵盖了贯穿 AI 全生命周期的规则、实践与技术 [14],旨在将透明性、问责制与公平性等原则嵌入系统设计,并在真实部署中推动公众监督与价值对齐。与将安全视为事后附加措施不同,AI 治理提倡对 AI 风险进行前瞻性、集成化管理 [15]。 更重要的是,AI 治理不仅仅是 AI 安全的延伸 [16]。AI 安全侧重于系统层面的稳健性,确保模型在分布偏移、对抗攻击或数据噪声下依然表现可靠;而治理的视野更为广阔,关注 AI 部署过程中的社会、伦理与制度层面。它涵盖了衍生风险,如隐私侵犯、虚假信息传播与算法歧视,同时引入法律责任、利益相关方问责机制与伦理审议等手段。因此,治理在技术与社会领域之间架起了桥梁,提供了一种既强大又可被负责任地控制的 AI 构建路径。 如图 1 所示,对相关文献的时间分布分析揭示了 LLM 治理研究领域的演化趋势。2017—2024 年间,该领域的学术关注度显著上升,尤其是 2020 年之后。预计到 2025 年底,相关学术论文数量将超过 8,000 篇,显示出 LLM 在现实应用中的快速部署已经引发了对其治理的迫切讨论。 尽管 AI 治理在学界、产业界和政策领域获得了越来越多关注,但一个能够跨越这些领域、系统整合且技术扎实的综合性综述仍然明显缺失。现有研究 [17], [18] 往往将技术安全与更广泛的治理问题割裂开来,或仅聚焦于特定风险(如公平性或对抗鲁棒性),缺乏统一的框架。同时,另一类主要源于伦理与法律研究的成果,虽然提供了高层次的规范性分析,但很少涉及新兴的实证评估方法、标准化基准与系统级防御手段 [18]。因此,迫切需要一篇综合性综述,以全面描绘 AI 治理的整体格局,并将其置于当代 AI 系统快速演进的背景之中。
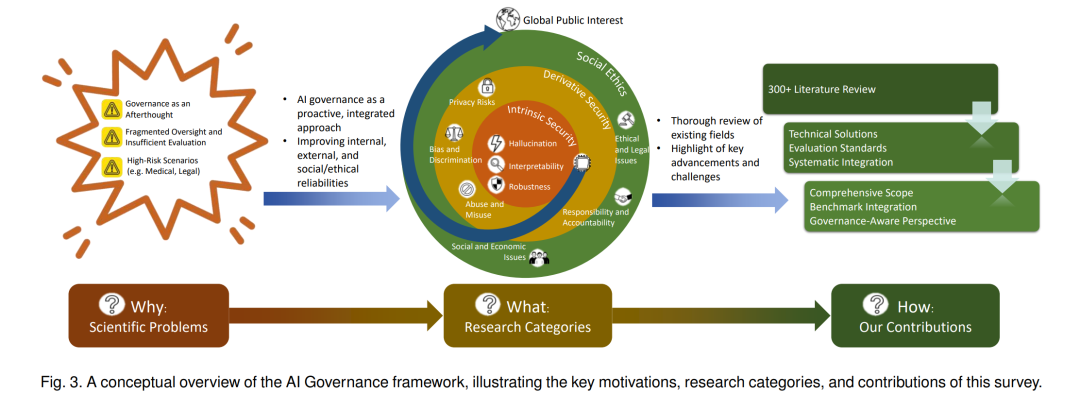
本研究正是在这种需求下提出的,旨在提供一份全面、系统的 AI 治理综述,构建一个贯通内生系统可靠性、衍生社会风险与规范治理机制的统一框架,为研究人员、开发者与政策制定者提供参考,从而确保 AI 系统既稳健可靠,又具备可问责性,并与公共利益保持一致。具体而言,我们试图回答三个关键问题: 1. 为何迫切需要研究 AI 治理? 我们识别出研究空白,即治理通常被视为事后补充而非核心设计原则,导致现有防御存在监管碎片化与评估不足的问题。这促使我们将 AI 治理定位为可信 AI 的基础。 1. 从大量现有工作中可以提炼出哪些开放挑战与未来治理指引? 我们定义了一个涵盖三大关键维度的统一治理框架:内生安全(如对抗鲁棒性、幻觉、可解释性)、衍生安全(如隐私、偏见、滥用)与社会伦理(如法律规范、问责机制、新兴伦理关注点)。借助该分类法,我们对技术与社会风险进行结构化的综合回顾。 1. 如何定义一个统一的治理框架? 我们系统回顾了 300 多篇参考文献,分析了视觉、语言与多模态系统中的代表性基准与评估指标,对比了现有方法的优劣,并综合提出开放挑战与未来研究方向。
这项多维度的综述为研究人员、工程师与政策制定者提供了可操作的洞见,帮助他们构建不仅稳健可靠,而且具备社会责任感与伦理对齐的 AI 系统,其整体结构如图 3 所示。 本研究的贡献总结如下: * 全面性:从技术视角对 AI 治理进行统一且系统的综述,涵盖内生安全(如对抗攻击、幻觉)、衍生安全(如隐私、偏见)与社会伦理(如伦理与法律问题)。 * 基准整合:整理并对比了相关的最新评测基准(如鲁棒性、幻觉、公平性与滥用检测等基准),促进治理相关主题的可复现研究与标准化评估。 * 治理导向视角:融合技术方法与社会及政策视角,推动 AI 系统设计与透明性、问责性及安全性等原则保持一致的治理框架发展。
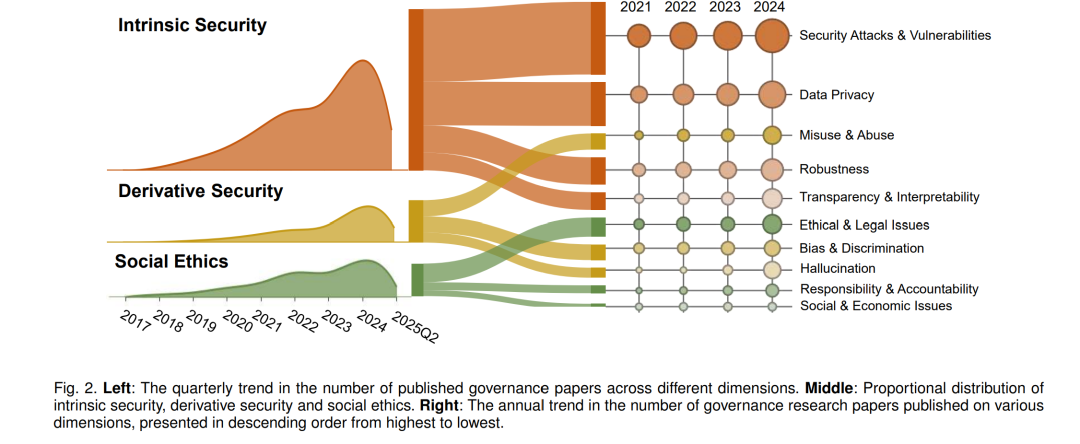
我们的综述围绕 AI 治理的三大支柱展开,即内生安全、衍生安全与社会伦理。具体而言(参见图 1):内生安全研究保持持续增长,尤其是在对抗性漏洞、模型鲁棒性与透明性方面。安全攻击与漏洞研究的论文数量从 2021 年的 230 篇增加到 2024 年的 353 篇,鲁棒性研究也呈类似上升趋势,反映了人们对对抗操纵与敏感数据保护的日益关注。尽管透明性与可解释性相关研究发表数量较少,但自 2017 年以来保持稳定,显示出学界持续探索理解与审计 LLM 行为的努力。相比之下,衍生安全(如隐私与虚假信息)在近几年获得了更快的关注增长。例如,虚假信息问题在 2021 年前几乎未被关注,但相关论文数量在 2024 年急剧上升至 249 篇,体现了提升 LLM 输出可信度的现实紧迫性。在社会伦理方面,偏见、责任与问责等主题的研究也在逐渐增多,显示其受到的关注度不断提升。 本文的剩余部分安排如下:第 2 节介绍 AI 治理的背景及其与 AI 安全的关系,强调其关键动机与基础原则;第 3 节讨论内生安全,包括对抗性漏洞、鲁棒性、幻觉与可解释性问题;第 4 节探讨衍生安全,重点关注隐私风险、偏见与歧视,以及滥用与误用问题;第 5 节涉及社会伦理,包括社会与经济影响、伦理与法律问题,以及责任与问责机制;第 6 节总结开放挑战与未来方向,包括技术缺口、监管与伦理考量以及研究机会;最后,第 7 节对本文进行总结。