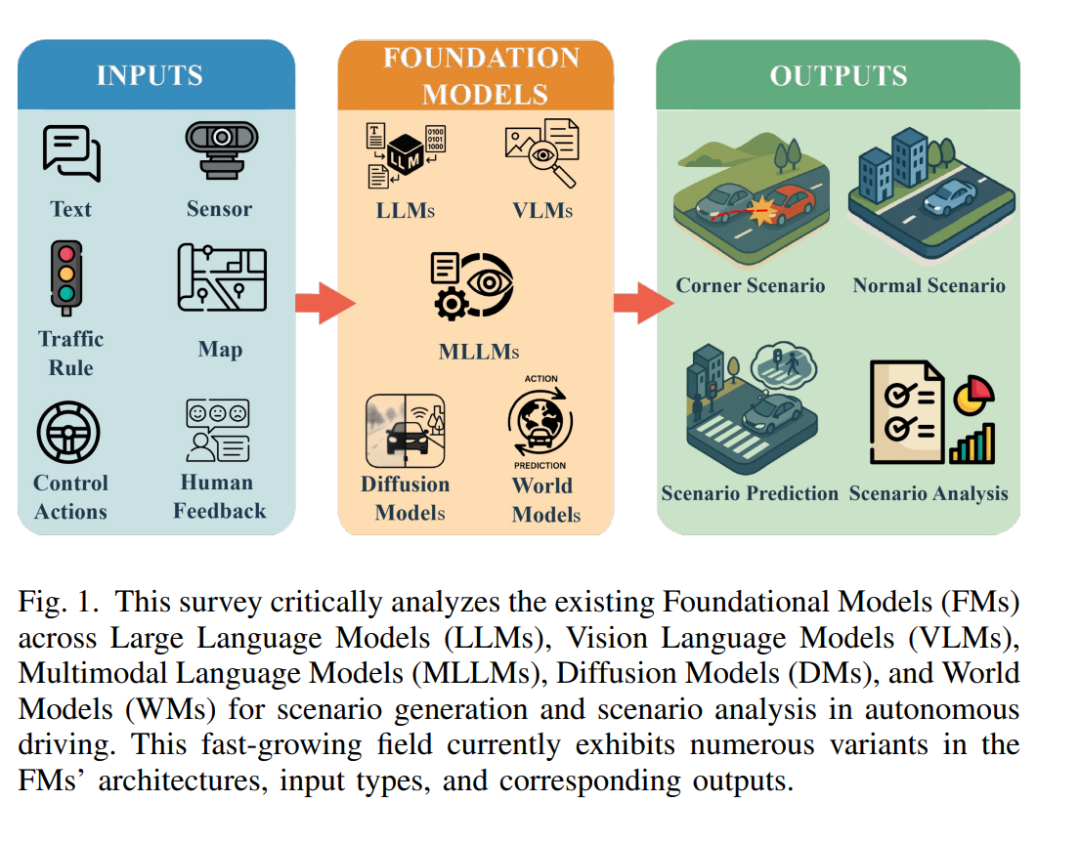
摘要——对于自动驾驶车辆而言,在复杂环境中实现安全导航依赖于其对多样化且罕见的驾驶场景的应对能力。基于仿真与场景的测试已成为自动驾驶系统开发与验证的关键方法。传统的场景生成依赖于基于规则的系统、知识驱动模型和数据驱动的合成方式,但这些方法往往生成的场景多样性有限,且难以覆盖逼真的安全关键情形。随着基础模型(即新一代预训练的通用人工智能模型)的兴起,开发者可以处理异构输入(例如自然语言、传感器数据、高精地图和控制动作),从而实现复杂驾驶场景的合成与理解。 本文针对基础模型在自动驾驶中的场景生成与场景分析应用(截至2025年5月)进行了系统综述。我们提出了一个统一的分类体系,涵盖大语言模型、视觉语言模型、多模态大语言模型、扩散模型和世界模型,用于自动驾驶场景的生成与分析。此外,本文还回顾了相关的方法论、开源数据集、仿真平台与基准挑战,并分析了专门面向场景生成与分析的评估指标。最后,我们总结了当前存在的关键挑战与研究问题,并提出了未来值得探索的研究方向。所有参考论文均收录于持续维护的资料库中,附带补充材料,托管于 GitHub.com/TUM-AVS/FM-for-Scenario-Generation-Analysis。
关键词——自动驾驶、场景生成、场景分析、基础模型、大语言模型。
一、引言
近年来,自动驾驶(Autonomous Driving, AD)取得了飞速发展,已达到在特定运行设计域(Operational Design Domains, ODDs)内几乎无需人类干预,甚至可完全自主运行的水平 [1]。Waymo 等公司自 2018 年起便已成功部署了具备 SAE L4 等级的全自动机器人出租车(robotaxi)服务 [2][3],在特定城市环境中验证了无人驾驶出行的可行性。截至 2025 年,Waymo 每周已提供约 250,000 次商业化出行服务 [4]。这一系列进展得益于高可靠性模块化自动驾驶软件功能的开发与严格验证,包括感知、预测、规划与控制等模块 [5]。 除了传统的模块化架构,近年来还涌现出基于深度学习的端到端学习方法 [6][7],可直接从原始传感器数据中生成轨迹或控制动作 [8]。
在仿真中进行的**基于场景的测试(scenario-based testing)**是评估和验证自动驾驶系统安全性与性能的关键手段 [9]。作为一种成本效益高的替代实地测试方式,它能够模拟真实、可复现且可控的驾驶环境 [10],尤其擅长重现那些在现实数据集中罕见或难以捕捉的安全关键情况(corner case)[11][12]。因此,系统化生成与分析驾驶场景的能力,对基于场景的测试至关重要,是自动驾驶功能(如感知、规划和控制)开发、验证与确认的重要支撑。
随着机器学习的不断发展,尤其是大规模基础模型(Foundation Models, FMs)的出现,自动驾驶中基于场景的测试在真实性、多样性与可扩展性方面迎来了新的机遇。基础模型由斯坦福大学人本人工智能研究所(HAI)于 2021 年 8 月首次提出 [13],用于描述一类在大规模多样化数据集上,通常采用自监督学习训练的模型。与传统机器学习模型通常针对特定任务进行训练不同,基础模型具备良好的迁移能力,可通过提示学习(prompting)或微调(fine-tuning)适应多种任务。这些模型已在多个领域取得卓越表现,包括自然语言处理(NLP)[14]、视觉理解 [15] 与代码生成 [16]。在自动驾驶领域,基础模型也日益受到关注,因为它们能够结合预训练阶段习得的通用知识与针对特定自动驾驶任务的高效适应能力 [17]–[19]。
A. 文献综述范围
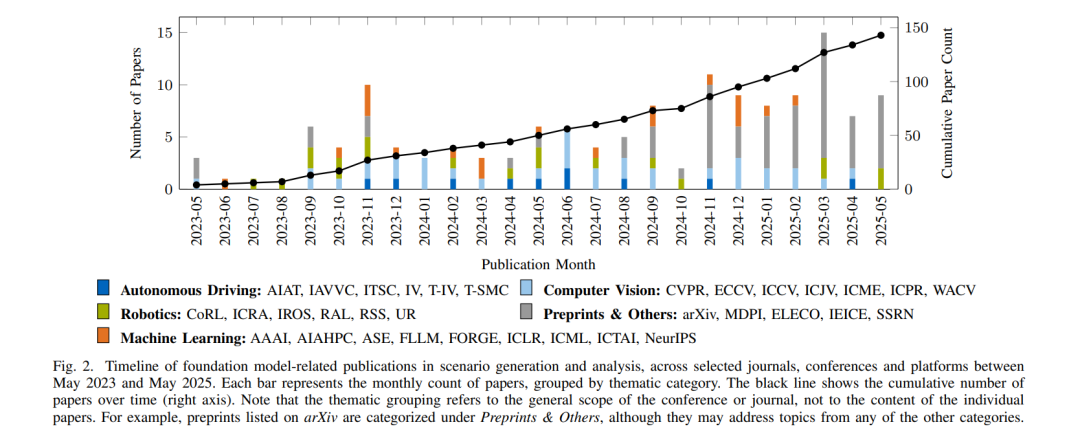
本综述聚焦于基础模型在自动驾驶场景生成与场景分析中的应用(参见图 1)。我们通过在 Google Scholar 中进行关键词检索(完整关键词列表见论文 GitHub 仓库)对相关文献进行筛选。 为了确保综述的广度与相关性,我们纳入了同行评审的会议与期刊论文,以及 arXiv 上的预印本。尽管 arXiv 上的论文未经过正式同行评审,但其在快速发展领域(如基础模型应用)中往往代表前沿且具有影响力的研究。我们调研的时间范围涵盖从 2022 年 10 月至 2025 年 5 月 之间发表的文献,重点关注自动驾驶、计算机视觉、机器学习/人工智能(AI)与机器人领域的研究成果。图 2 展示了按月统计的发表数量及其在不同类型平台(会议、期刊或预印本)中的分布趋势。每篇文献的发表平台及其开源代码(如有)均在论文 GitHub 仓库中列出。
B. 综述结构安排
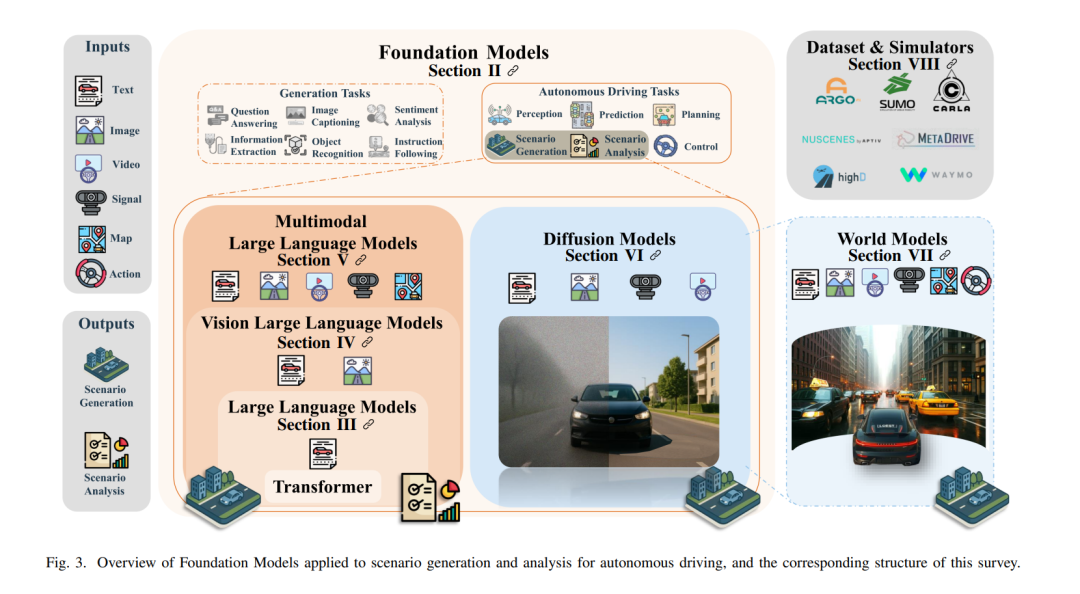
本综述的整体结构如图 3 所示: * 第 II 节介绍基础模型,并对已有关于场景生成与分析的相关综述进行评述,涵盖经典方法与基础模型驱动的最新进展; * 第 III、IV、V 节系统探讨语言类基础模型,从基本概念出发,详细分析大语言模型(LLMs)、视觉语言模型(VLMs)和多模态大语言模型(MLLMs)在场景生成与分析中的应用; * 第 VI 与 VII 节聚焦于视觉为中心的基础模型,分别介绍扩散模型与世界模型的基本原理及其与场景生成的关联; * 第 VIII 节调研当前可公开获取的数据集与仿真基准,重点介绍与自动驾驶场景生成与分析密切相关的竞赛与挑战; * 第 IX 和 X 节归纳当前的研究难点与开放性问题,并展望未来的研究方向; * 第 XI 节总结本综述的核心发现与主要观点。