
摘要
现代推荐系统运行于高度动态的环境中:用户兴趣、物品库和流行趋势持续演变,模型必须实时适应且不遗忘历史偏好。尽管现有关于持续学习或终身学习的教程涵盖机器学习多个领域(如视觉与图数据),但尚未涉及推荐系统的特定需求——例如针对每位用户平衡稳定性与可塑性、处理冷启动物品、在流式反馈下优化推荐指标等。本教程旨在及时填补这一空白。 首先我们将回顾背景知识与问题设定,继而系统梳理现有方法体系,包括基于回放与基于正则化的技术路径。接着重点介绍将持续学习应用于实际部署环境的最新进展,涵盖资源受限系统与序列交互场景等实践场景。最后深入探讨开放挑战与未来研究方向。我们相信本教程将为推荐系统、数据挖掘与人工智能领域的研究者及实践者提供重要参考,并惠及与信息检索相关的众多实际应用领域。 听众需具备概率论、线性代数与机器学习基础知识,无需预先掌握特定持续学习算法。 大纲与时间安排
本教程为期半天,总时长约3小时(含短暂休息),具体安排如下: 第一部分:引言与背景知识(30分钟)[幻灯片] * 问题定义与基础设定 * 核心挑战剖析 * 应用场景与典型案例
第二部分:基于经验回放的方法(35分钟)[幻灯片] * 回放样本选择策略 * 基于回放的模型增强技术
第三部分:基于正则化的方法(35分钟)[幻灯片] * 关键知识正则化目标 * 时序知识正则化机制 * 个性化正则化方案
第四部分:超越传统设定(35分钟)[幻灯片] * 资源受限环境下的适配 * 终身序列环境处理 * 联邦学习场景应用
第五部分:开放挑战与未来方向(35分钟)[幻灯片] * 大语言模型与生成式推荐 * 可信推荐体系构建 * 基础模型适配策略
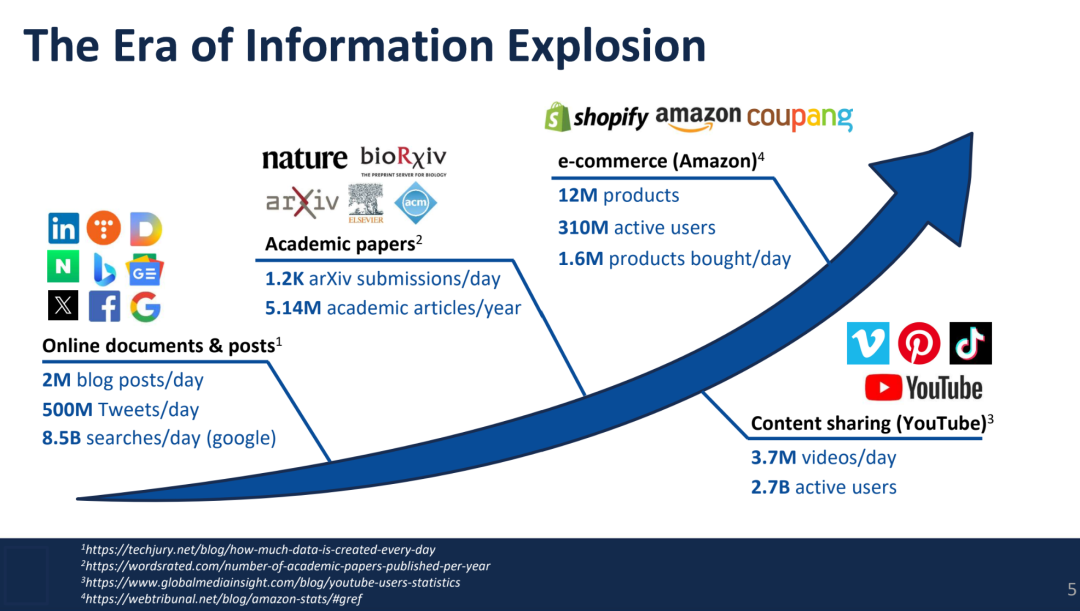
成为VIP会员查看完整内容
相关内容
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日


相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日