

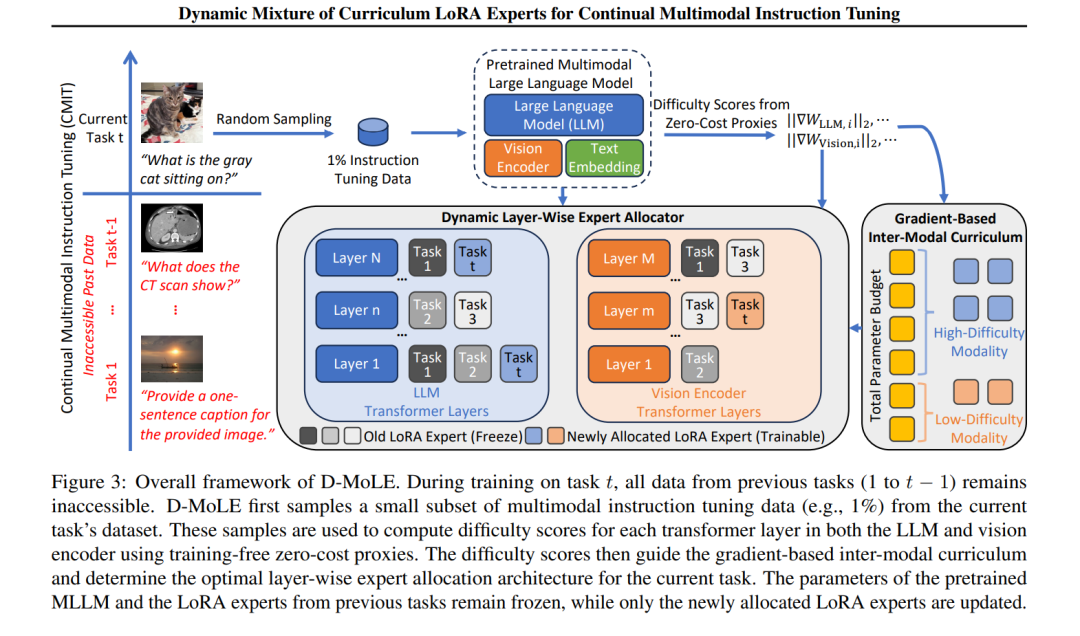
持续多模态指令微调对于使多模态大语言模型(Multimodal Large Language Models,简称 MLLMs)适应不断变化的任务至关重要。然而,大多数现有方法采用固定的模型架构,因其静态的模型容量,难以有效适应新任务。为此,我们提出在参数预算限制下进化模型架构以实现动态任务适应,这一方向尚未被充分探索,并带来了两个主要挑战:1)任务架构冲突:不同任务在层级适配上存在差异化需求;2)模态不平衡:不同任务对各模态依赖程度不同,导致更新过程不均衡。 为应对上述挑战,我们提出了一种新颖的方法:动态课程化 LoRA 专家混合机制(D-MoLE),该方法在受控参数预算下自动进化 MLLM 的架构,以持续适应新任务,同时保留已学知识。具体而言,我们设计了一种动态层级专家分配器,该模块可自动在各层之间分配 LoRA 专家,以解决架构冲突问题,并按层级方式路由指令以促进专家之间的知识共享。随后,我们进一步提出一种基于梯度的跨模态持续课程机制,该机制根据任务中各模态的难度调整 MLLM 各模块的更新比例,从而缓解模态不平衡问题。 大量实验表明,D-MoLE 在多个基准任务中显著优于当前最先进的方法,平均提升达 15%。据我们所知,这是首个从架构角度出发,对 MLLM 进行持续学习的研究。
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
211+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日

相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
211+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日