
转载机器之心 编辑:张倩
生成模型会重现识别模型的历史吗?
今年的 CVPR 已经在美国田纳西州纳什维尔顺利闭幕。除了交流论文、互加好友,很多参会者还参加了个非常有意思的项目 —— 追星。
这个「星」自然是学术明星。从前方发来的实况来看,MIT 副教授何恺明可能是人气最高的那一个。他的讲座全场爆满,还有很多同学晒出了与恺明大神的合影。
其实,这次现身 CVPR 会场的何恺明有着多重身份,包括但不限于最佳论文奖委员会成员、「Visual Generative Modeling: What’s After Diffusion?」workshop 演讲嘉宾等。

这个 workshop 聚焦的主题是扩散模型之后的视觉生成建模演进方向。
近年来,扩散模型迅速超越了先前的方法,成为视觉生成建模中的主导方法,广泛应用于图像、视频、3D 物体等的生成。然而,这些模型也存在一些显著的局限性,例如生成速度较慢、生成过程中人类干预有限,以及在模拟复杂分布(如长视频)时面临挑战。
这个 workshop 旨在探索视觉生成建模中能够超越扩散模型的方法,何恺明在活动中做了主题为「Towards End-to-End Generative Modeling(走向端到端生成建模)」的分享。
近日,他的个人网页上传了 workshop 的 PPT,非常值得学习。

PPT 地址:https://people.csail.mit.edu/kaiming/cvpr25talk/cvpr2025_meanflow_kaiming.pdf
走向端到端生成建模
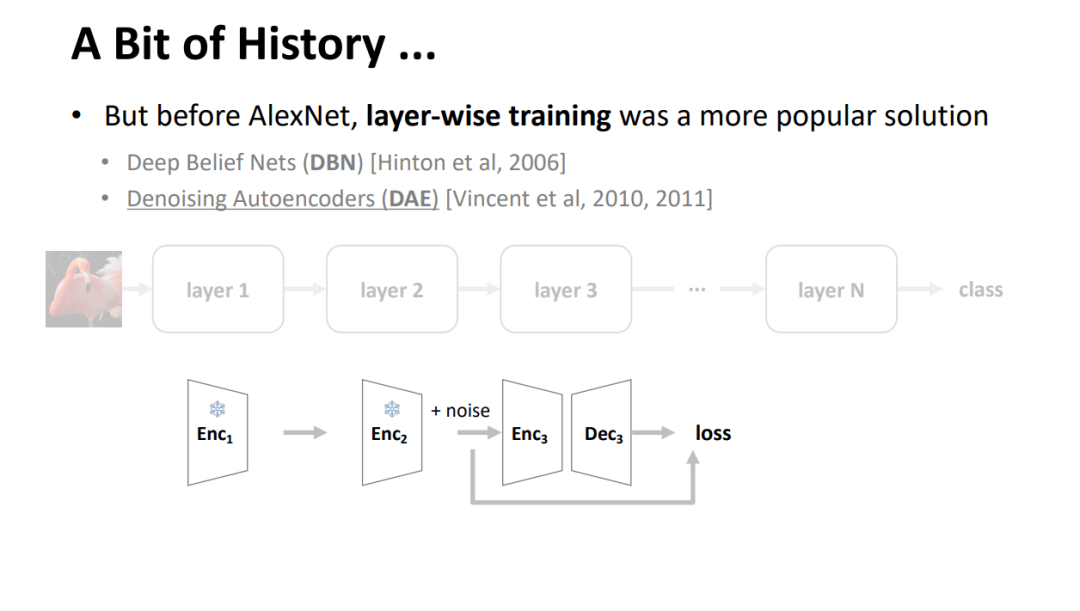
在 PPT 前几页,何恺明首先带大家回顾了识别模型(recognition model)的演进。在 AlexNet 之前,逐层训练更为流行,如深度信念网络(DBN)和去噪自编码器(DAE)。但 AlexNet 之后,识别模型普遍实现了端到端训练,大大简化了模型设计和训练的复杂性。




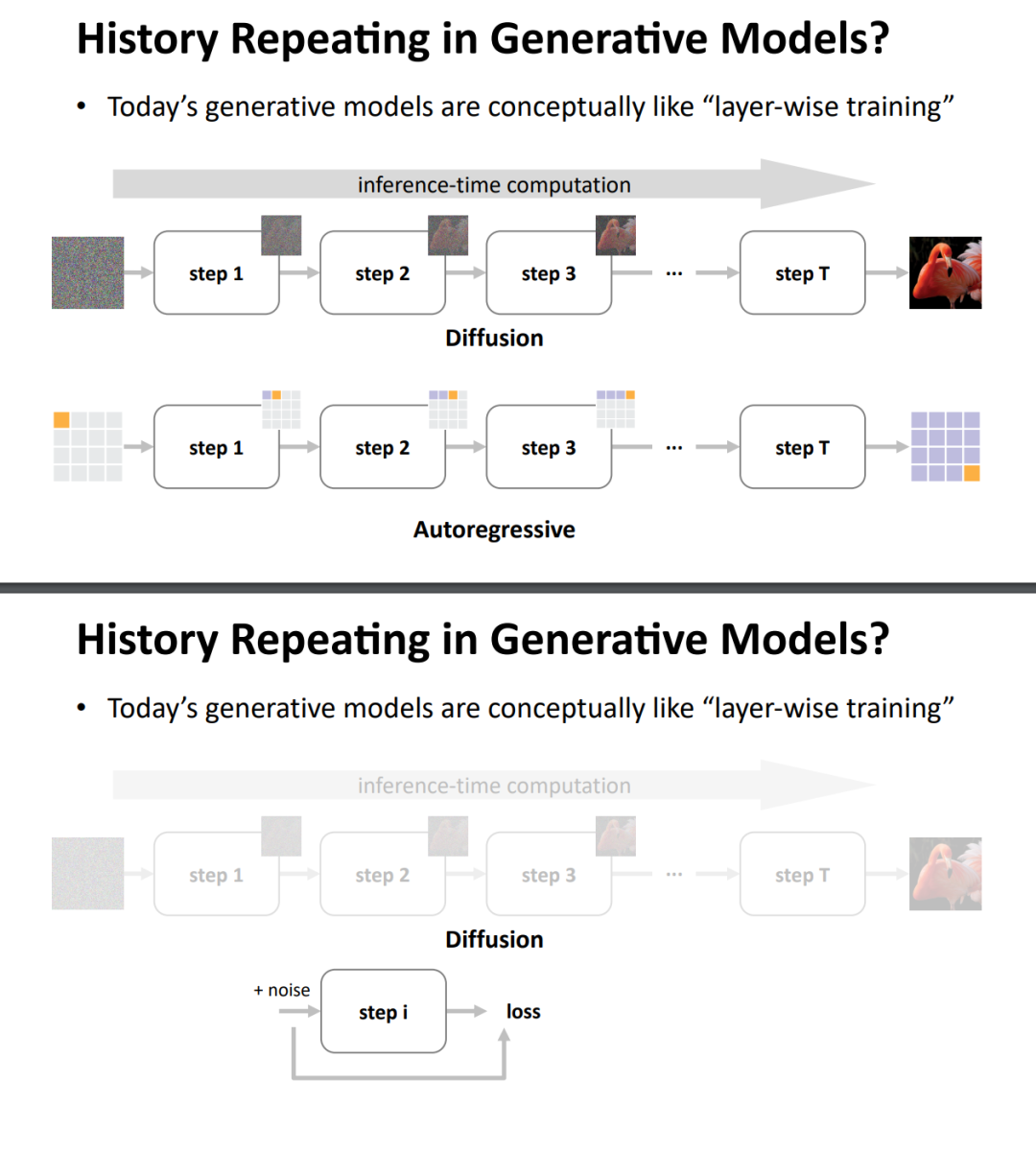
有趣的是,今天的生成模型在概念上更像是逐层训练:Diffusion 模型通过 T 个去噪步骤逐步生成,自回归模型通过 T 个 token 逐步生成,它们都需要多步推理过程。这让我们不禁思考:历史能否在生成模型领域重演?
从更高层面来看,识别与生成其实是同一枚硬币的两面。识别可以被看作是一个「抽象」的过程:我们从丰富的原始数据(如图像像素)出发,通过网络的多层处理,逐步提取出越来越抽象的特征,直到最终得到一个高度抽象的分类标签或嵌入。
而生成则恰恰相反,它是一个「具体化」的过程:我们从一个抽象的表示(比如一个随机噪声或概念向量)开始,通过网络的多步转换,逐渐将其具体化,最终生成出具有复杂细节的真实数据。
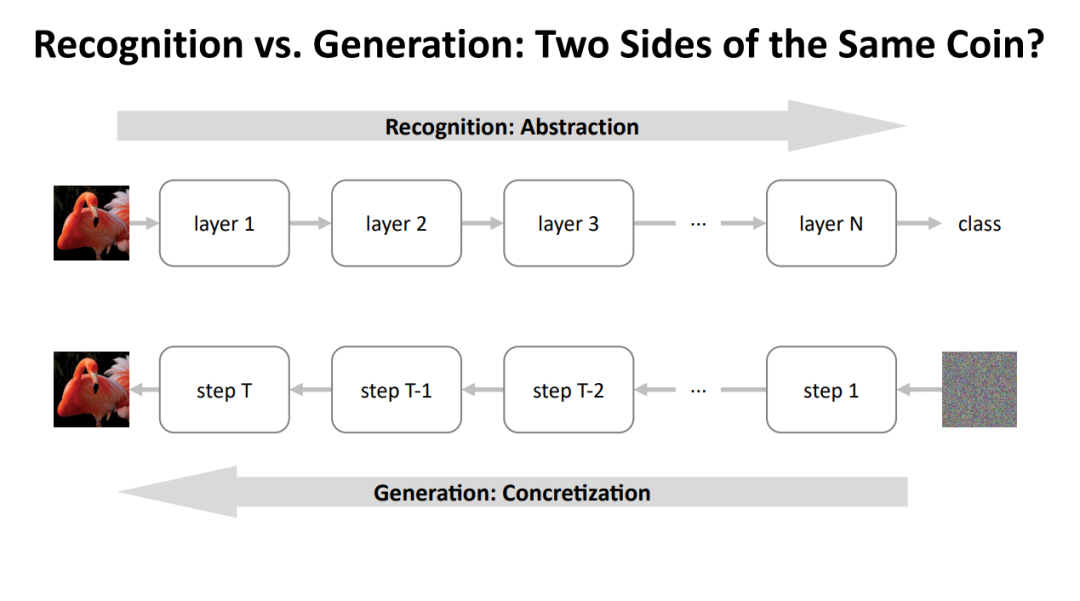
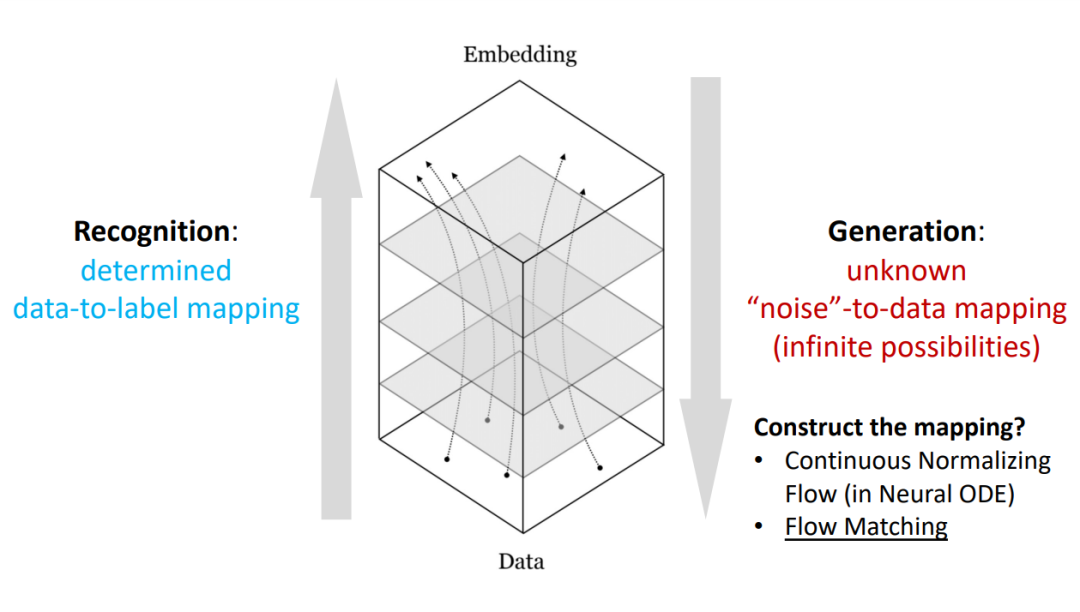
下图更直观地描绘了这种「抽象」与「具体化」的对应关系。底部代表原始数据,顶部代表抽象的嵌入空间。表示学习是从数据向上流动,将数据映射到嵌入。而生成建模则是从嵌入向下流动,将嵌入转换为数据。这个过程可以被视为数据在不同抽象层次之间的「流动」。
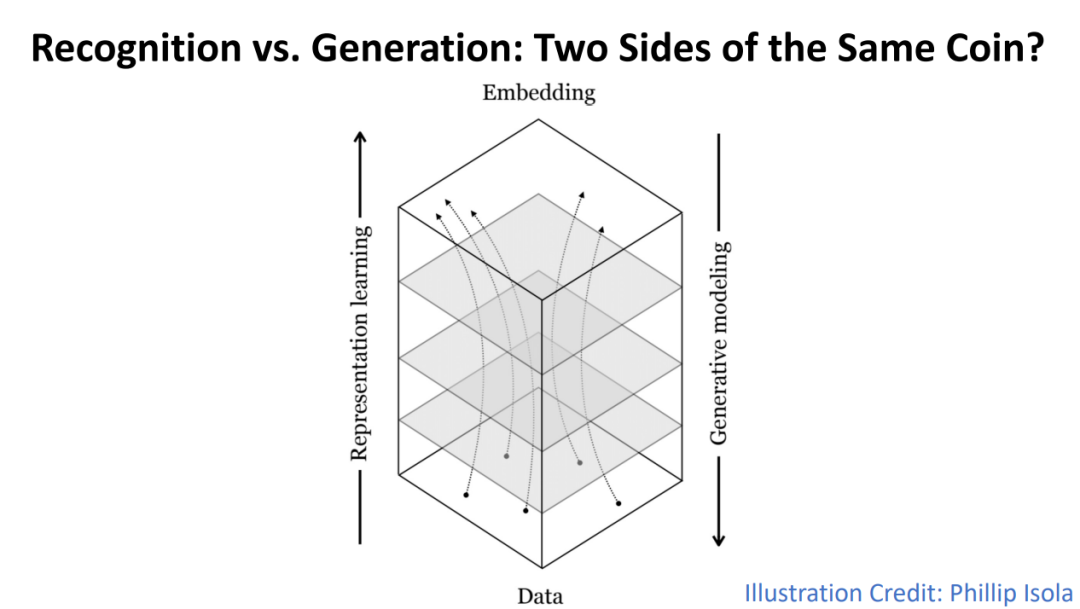
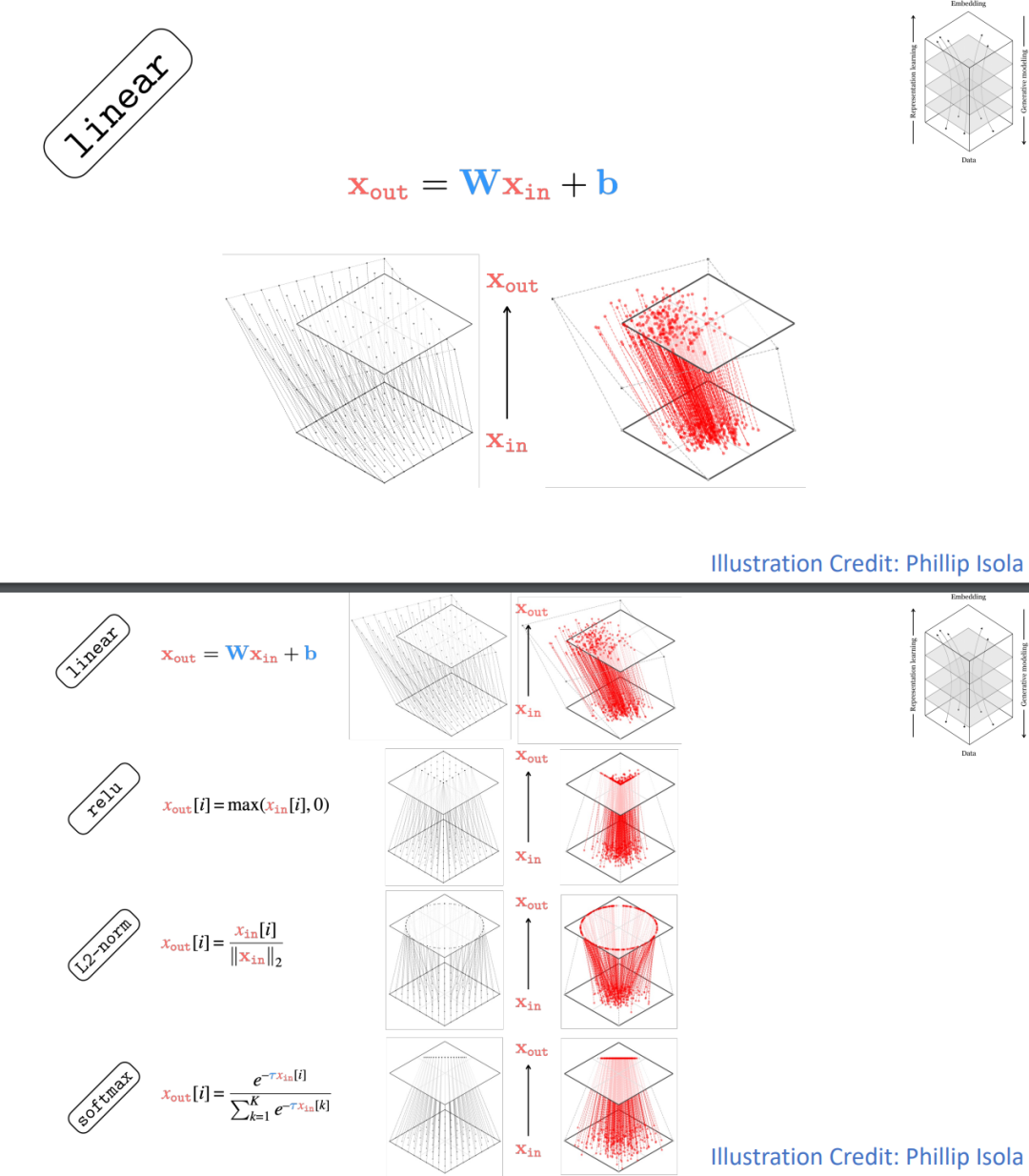
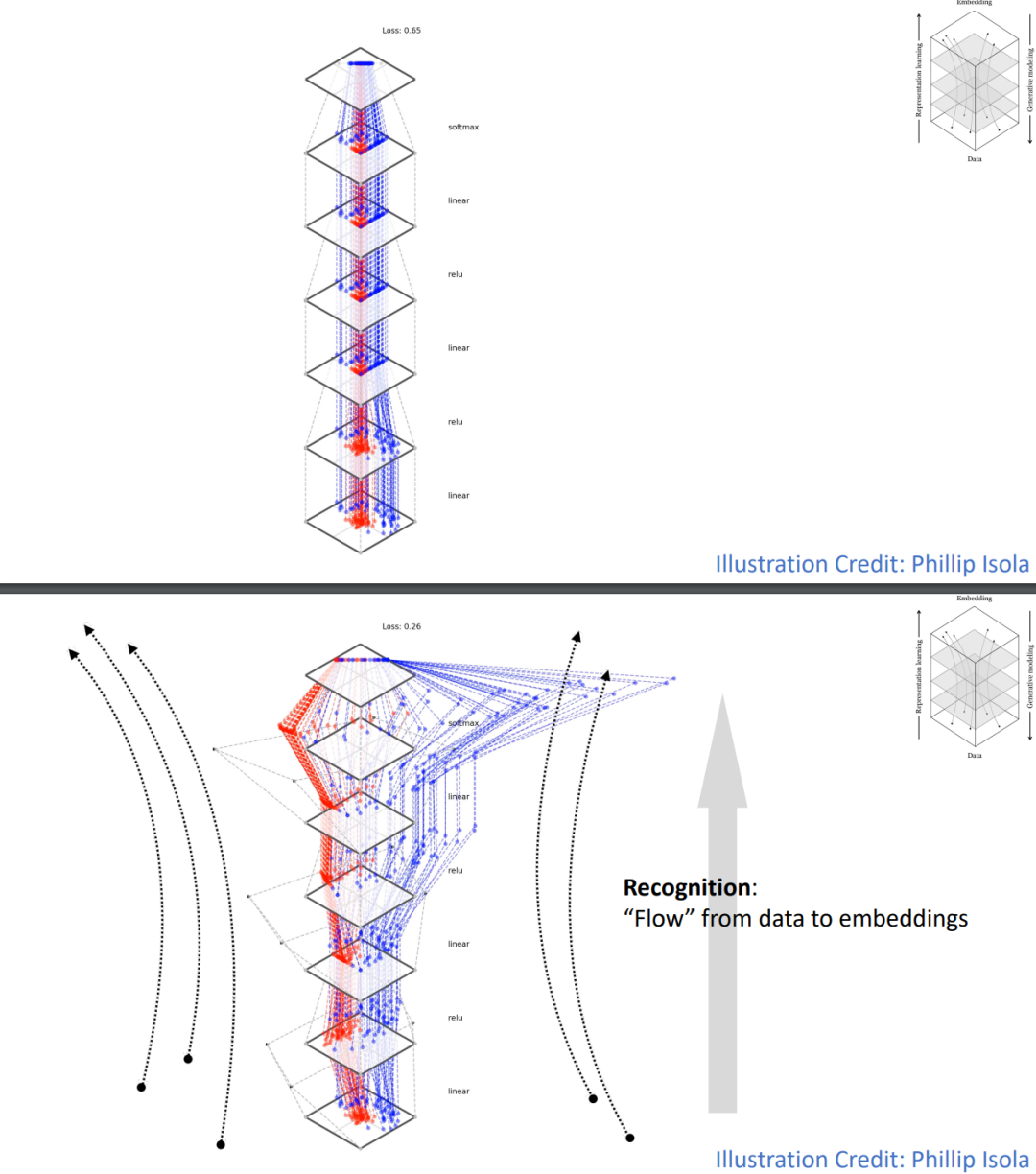
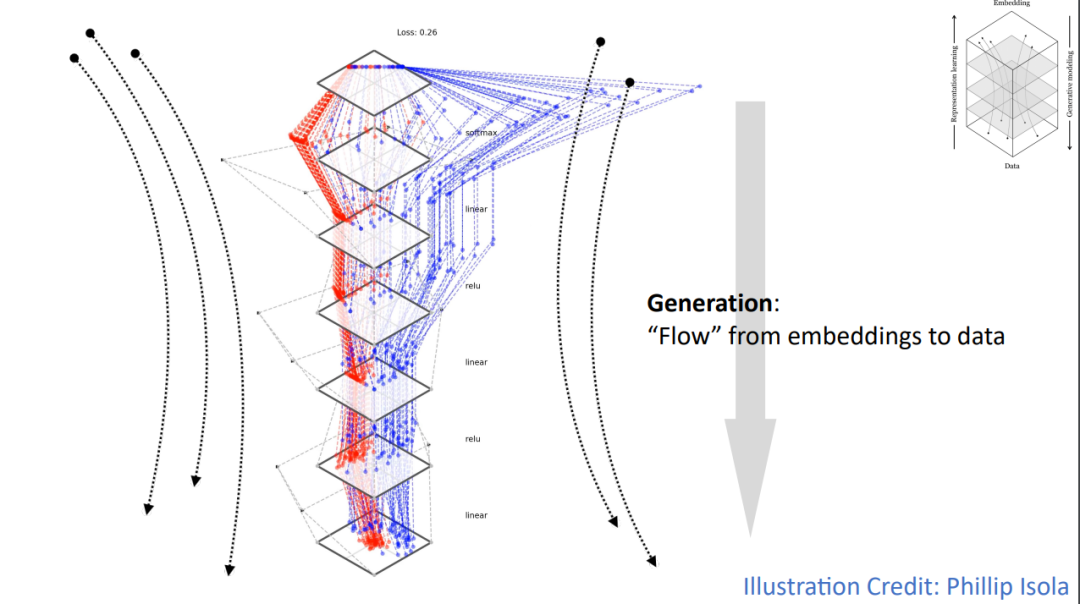

不过,识别和生成和生成有着本质的不同。识别任务通常有一个确定的数据到标签的映射,但生成任务不然:我们希望从一个简单的「噪声」分布映射到复杂多变的数据分布。这个映射是高度非线性的,而且存在无限的可能性。
如何有效地「构造」这个映射,是生成模型面临的核心挑战。连续归一化流(Continuous Normalizing Flow),尤其是其中衍生的「流匹配」(Flow Matching)技术,为解决这个问题提供了有希望的方向。
在讲座中,何恺明提到了流匹配方向的几篇代表性论文:

下图直观地展示了 Flow Matching 在生成模型领域中的位置:
何恺明还介绍了流匹配的一些技术细节:


讲到这里,何恺明总结出了几个关键点:
识别与生成都可以被视为数据分布之间的一种「流」。 * Flow Matching 为训练生成模型提供了一种强大的方法,它能够构建出 ground-truth 场,这些场是隐式存在的,并且与具体的神经网络结构无关。 * 尽管我们希望实现精确的积分来生成,但在实践中,我们通常采用有限求和的近似,这与 ResNet 的离散化方法类似,或者利用数值 ODE 求解器。 * 我们的终极目标是实现前馈式的、端到端的生成建模,摆脱多步迭代的依赖。

接下来,何恺明介绍了他们近期提出的新方法 ——「Mean Flows for One-step Generative Modeling」。它的核心思想是追求一步到位的生成。

具体来说,论文提出了一种名为 MeanFlow 的理论框架,用于实现单步生成任务。其核心思想是引入一个新的 ground-truth 场来表示平均速度,而不是流匹配中常用的瞬时速度。
论文推导出平均速度与瞬时速度之间存在一个内在的关系,从而作为指导网络训练的原则性基础。
基于这一基本概念,论文训练了一个神经网络来直接建模平均速度场,并引入损失函数来奖励网络满足平均速度和瞬时速度之间的内在关系。
以下是该论文的技术细节(可参见机器之心之前的报道辅助理解:《何恺明团队又发新作: MeanFlow 单步图像生成 SOTA,提升达 50%》:










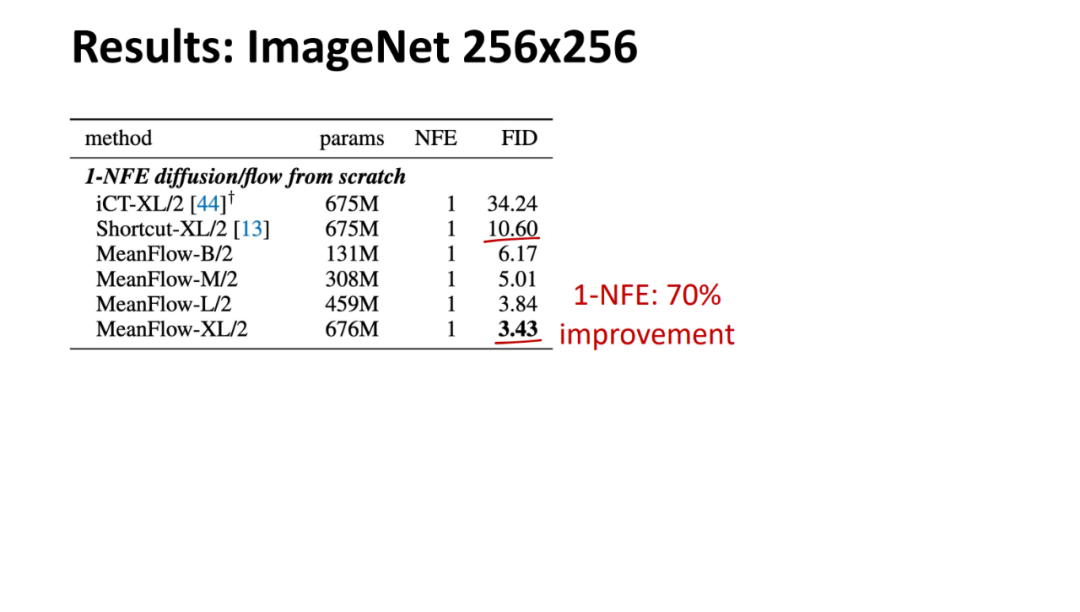
论文所提方法的实验结果如下。MeanFlow 与之前的单步扩散 / 流模型进行了比较,总体而言,MeanFlow 的表现远超同类:它实现了 3.43 的 FID,与 IMM 的单步结果 7.77 相比,相对提升了 50% 以上。如果仅比较 1-NFE(而不仅仅是单步)生成,MeanFlow 与之前的最佳方法(10.60)相比,相对提升了近 70%。不难看出,该方法在很大程度上缩小了单步和多步扩散 / 流模型之间的差距。
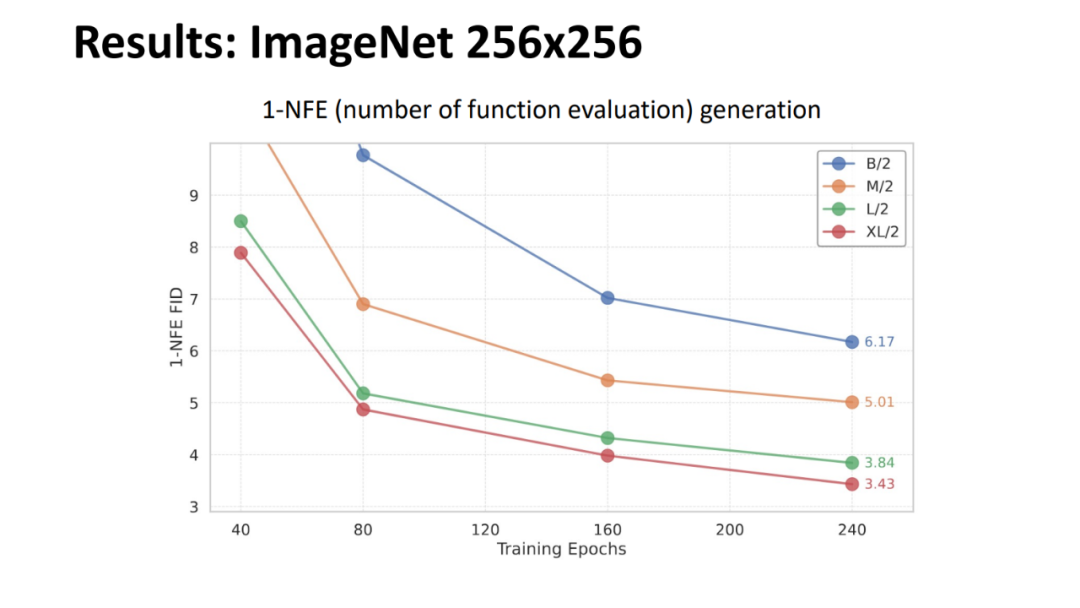
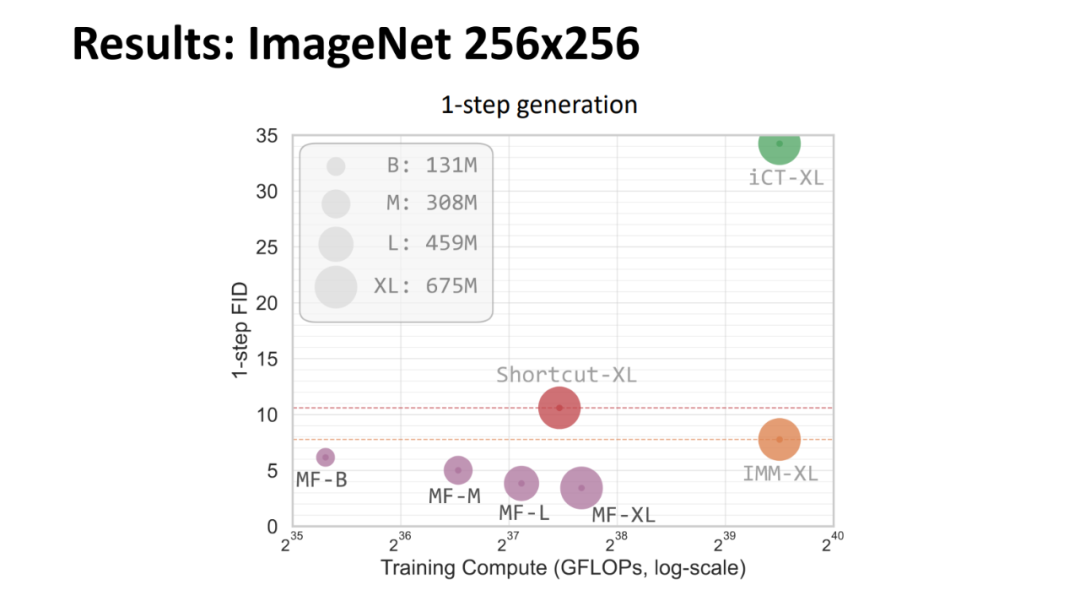


然后,他展示了一些 1-NFE 的生成结果。

接下来,何恺明致敬了整个社区在实现高效、端到端生成方面所做的共同努力。他列举了几个主要的研究方向:
Consistency Models (CM):包括 Song 等人的原始工作,以及后续的改进版本如 iCT、ECT、sCM。 * Two-time-variable Models:例如 Consistency Trajectory Models (CTM)、Flow Map Matching、Shortcut Models 和 Inductive Moment Matching。 * Revisiting Normalizing Flows:如 TarFlow 等。

最后,何恺明对整个方向进行了展望,并提出了几个问题:
我们是否还在生成模型的「AlexNet 前时代」? * 尽管 MeanFlow 已经取得了显著的进步,但它在概念上仍然受限于迭代的 Flow Matching 和扩散模型框架。 * MeanFlow 网络扮演着双重角色:它既要构建从噪声到数据的理想轨迹(这些轨迹是隐式存在但需要模型去捕捉的),又要通过「粗化」或概括这些场来简化生成过程。 * 那么,究竟什么是真正适用于端到端生成建模的良好公式?这是一个开放性的、激动人心的研究问题。


