

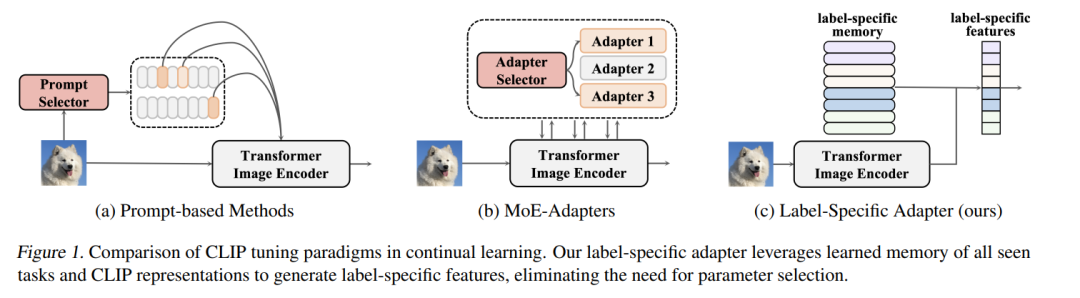
用类似 CLIP 的视觉-语言模型进行持续学习,为构建可扩展的机器学习系统提供了新途径,主要得益于其强大的可迁移表示能力。现有基于 CLIP 的方法通常通过为每个任务添加一组或多组可学习参数来适配预训练的图像编码器,推理时需选择对应任务的参数集。然而,这种做法在推理阶段容易出错,进而导致性能下降。 为解决这一问题,本文提出了 LADA(Label-specific ADApter,标签特定型适配器)。与以往方法按任务划分参数不同,LADA 在冻结的 CLIP 图像编码器后追加了轻量级的、标签特定的记忆单元。这些记忆单元可整合任务无关的知识,生成更具判别性的特征表示。
为了避免灾难性遗忘,LADA 针对已学习类别引入了特征蒸馏机制,防止新类的学习对旧类特征造成干扰。由于 LADA 被设计在图像编码器之后,其训练过程中不会将梯度反向传播至冻结的 CLIP 参数,从而保证了训练效率。
大量实验结果表明,LADA 在持续学习任务中达到了当前最优的性能。代码已开源,地址为: 👉 https://github.com/MaolinLuo/LADA
成为VIP会员查看完整内容
相关内容
Arxiv
210+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
210+阅读 · 2023年4月7日