

在强化学习(RL)中,智能体不断与环境交互,并利用反馈来改进其行为。为了引导策略优化,引入奖励模型作为期望目标的代理,使得当智能体最大化累积奖励时,也能切实满足任务设计者的意图。近年来,学术界和工业界的研究者都聚焦于构建既能与真实目标高度对齐,又能促进策略优化的奖励模型。 本文综述对深度强化学习领域中的奖励建模技术进行了系统回顾。我们首先介绍奖励建模的背景与基础知识;随后,以“来源”“机制”和“学习范式”为维度,对最新的奖励建模方法进行分类梳理;在此基础上,探讨这些技术的多种应用场景,并回顾评估奖励模型的常用方法。最后,我们总结了值得关注的未来研究方向。 总体而言,本综述涵盖了既有方法与新兴方法,填补了当前文献中缺乏系统性奖励模型综述的空白。
1 引言
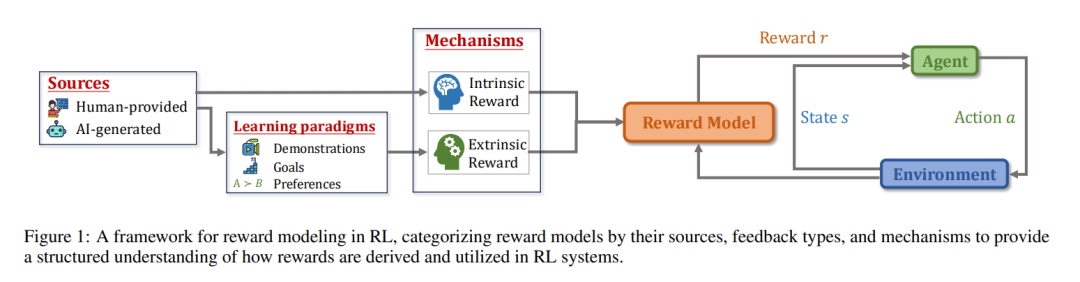
近年来,**深度强化学习(Deep Reinforcement Learning, DRL)**这一结合了强化学习(RL)与深度学习(DL)的机器学习范式,在多个领域的应用中展现出巨大潜力。例如,AlphaGo [Silver et al., 2016] 展示了强化学习在博弈类场景中进行复杂决策的能力;InstructGPT [Ouyang et al., 2022] 强调了强化学习在对齐语言模型与人类意图中的不可替代作用;通过大规模强化学习训练的智能体,如 OpenAI-o1 和 DeepSeek-R1 [Guo et al., 2025],展现出了与人类相当甚至超越人类的推理智能。与监督学习(SL)中要求智能体模仿和复现数据集中的行为不同,强化学习的核心优势在于使智能体能够基于自身行为的结果进行探索、适应与优化,从而实现前所未有的自主性和能力。 奖励机制是强化学习的核心组成部分,实质上定义了任务中的目标,并引导智能体优化其行为以达成该目标 [Sutton et al., 1998]。正如多巴胺在生物系统中激励和强化适应性行为一样,强化学习中的奖励鼓励智能体探索环境,引导其朝向期望的行为发展 [Glimcher, 2011]。然而,尽管在研究环境中奖励函数通常是预先定义好的 [Towers et al., 2024],但在许多真实世界的应用中,奖励往往不存在或难以明确指定。因此,当代强化学习研究的一个重要方向,是如何从多种类型的反馈中提取有效的奖励信号,以便后续使用标准的强化学习算法对智能体策略进行优化。 尽管奖励建模在强化学习中扮演着至关重要的角色,现有的综述文献 [Arora and Doshi, 2021; Kaufmann et al., 2023] 通常聚焦于特定子领域,如逆强化学习(IRL)与基于人类反馈的强化学习(RLHF),而较少将奖励建模作为一个独立课题进行系统梳理。为填补这一空白,本文对奖励模型进行了系统性回顾,涵盖其理论基础、关键方法和在多种强化学习场景中的应用。我们提出了一个新的分类框架,用以回答以下三个基本问题: 1. 来源(The source):奖励来自哪里? 1. 机制(The mechanism):是什么驱动智能体的学习? 1. 学习范式(The learning paradigm):如何从不同类型的反馈中学习奖励模型?
此外,我们特别关注了基于基础模型(如大语言模型 LLMs 与视觉-语言模型 VLMs)的奖励建模的最新进展,该方向在已有综述中关注较少。本文所构建的奖励建模框架如图 1 所示。 具体而言,本文的结构安排如下: 1. 奖励建模背景(第2节):介绍强化学习与奖励模型的基础知识; 1. 奖励模型的分类(第3至第5节):提出奖励建模的分类框架,分别从来源(第3节)、学习驱动机制(第4节)以及学习范式(第5节)三个维度进行划分。同时,我们在表1中列出了近期相关文献,并依照该框架进行归类; 1. 应用与评估方法(第6与第7节):探讨奖励模型在实际场景中的应用,以及常用的评估方法; 1. 未来方向与讨论(第8节):总结全文,并展望该领域的潜在研究方向。
