与大多数传统推荐问题不同,序列推荐侧重于通过利用交互项目之间的内在顺序和依赖关系来学习用户的偏好,这一研究方向已经引起了研究人员和实践者的广泛关注。近年来,该领域取得了显著的进展和成果,迫切需要一项新的综述。在本综述中,我们从一个新的视角(即物品属性的构建)研究序列推荐问题,并总结了序列推荐中最先进的技术,如基于ID的纯序列推荐、带有辅助信息的序列推荐、多模态序列推荐、生成式序列推荐、LLM驱动的序列推荐、超长序列推荐和数据增强的序列推荐。此外,我们还介绍了序列推荐的一些前沿研究话题,例如开放领域序列推荐、数据中心序列推荐、云端协作序列推荐、持续序列推荐、公益序列推荐和可解释的序列推荐。我们相信,本综述可以为该领域的读者提供一份宝贵的路线图。关键词
序列推荐,基于ID的,辅助信息,最新进展,新问题https://www.zhuanzhi.ai/paper/21d9c1b99e82eb5c8e964d911ef93e3b
1 引言
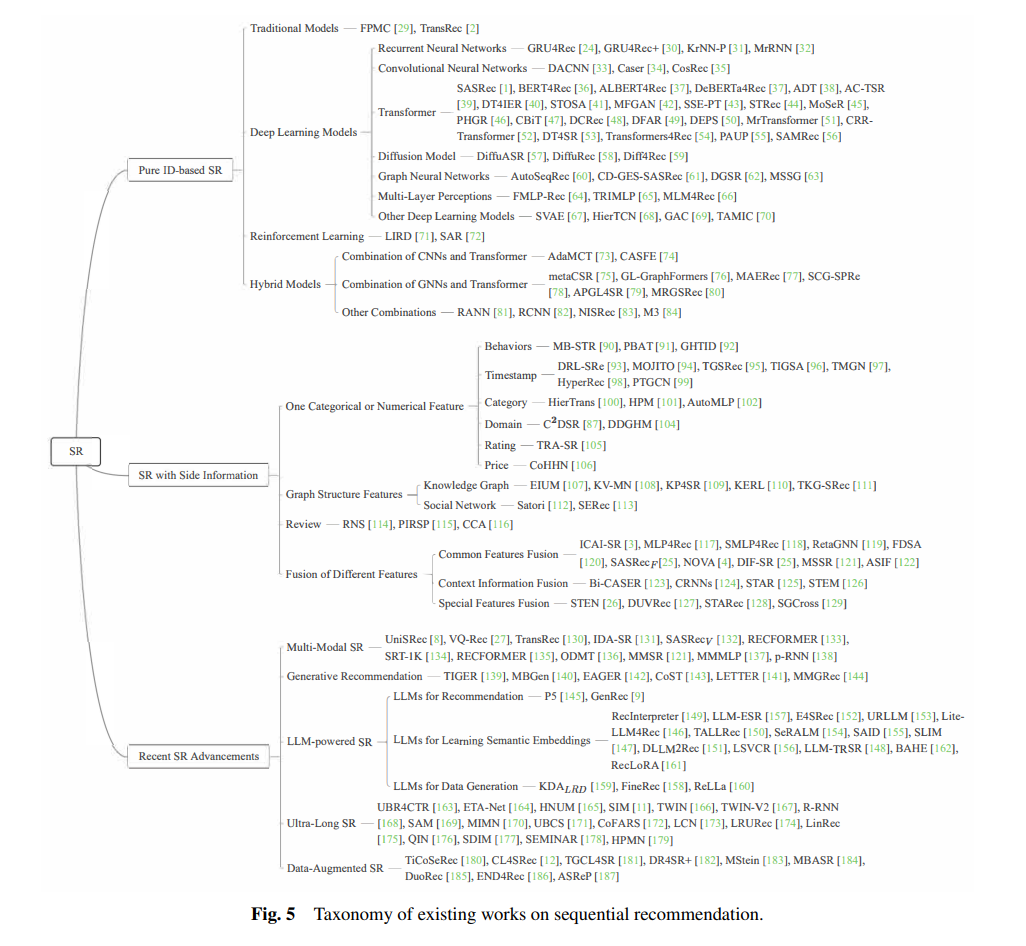
推荐系统通常旨在从大量项目中为用户推荐其感兴趣的项目,以解决信息过载问题并节省用户时间。同时,推荐系统通常被认为在通过激励用户购买他们感兴趣的项目方面能够有效提高商业利润。迄今为止,推荐系统已在各种现实世界的应用中得到部署,例如电子商务(如 Amazon 和 Alibaba)、流媒体服务(如 YouTube 和 TikTok)、社交媒体(如 WeChat 和 Twitter)、在线广告等。近年来,已经提出了各种序列推荐(SR)模型,并在性能上取得了显著的提升[1]。SR模型的主要思想是利用交互项目的位置信息或顺序信息,以捕捉它们之间的依赖关系。给定一个用户的交互序列,典型的SR模型旨在预测该用户下一个可能偏好的项目。近年来,SR模型的数量显著增加。通过在DBLP网站1)中搜索关键词(即“序列”,“推荐”),我们得到了有关序列推荐的论文的具体出版数量,见图1。可以看到,关于序列推荐的论文数量随着时间的推移而增加。需要注意的是,2024年发表的论文数量略少于2023年,因为我们是在2024年6月12日收集的数据。一些早期的SR模型[1, 2]使用唯一的ID来表示一个项目。这些SR模型简单而有效。对于每个项目,SR模型通常需要学习一个唯一的项目嵌入,这通常是高效的。同时,项目嵌入可以捕捉项目之间的相关性,并提取它们的潜在特征。然而,这些SR模型也存在一些缺点。例如,仅使用项目ID无法解决冷启动和稀疏性问题。因此,一些SR模型[3, 4]结合了项目ID和项目特征。项目特征主要包括类别特征(例如,类别)、数值特征(例如,价格)和图结构特征(例如,社交网络和知识图谱)。由于隐私问题,我们通常对用户了解较少。通过利用这些特征,我们可以有效地学习项目表示,即使与某些项目的交互是稀疏的。因此,这些SR模型可以缓解冷启动和数据稀疏问题。然而,这些SR模型也有一些局限性。例如,它们通常在训练过程中严重依赖项目ID。如果数据不同,则项目ID也不同。因此,在一个数据集上训练的模型不能轻易地通过微调或其他方法迁移到另一个数据集。随着自然语言处理和计算机视觉的快速发展,像BERT[5]和ResNet[6]这样的模型可以从文本描述和图像中提取丰富的特征。为了解决数据依赖性问题,一些SR模型[7, 8]利用BERT和ResNet分别从文本描述和图像中提取项目的语义表示,然后直接使用这些表示来表示项目。由于多模态特征的广泛可用性,这些在某个平台上的训练模型可以通过微调在另一个平台上部署。然而,从多模态特征中提取的语义表示无法完全捕捉用户的细粒度偏好和协作信号。因此,一些SR模型转向将多模态特征与项目ID结合,以更全面地学习用户的偏好。大语言模型(LLMs)通过使用大量数据进行训练,并展示出令人期待的性能。更重要的是,LLMs具有强大的推理能力。因此,LLMs已被应用于许多应用场景,包括推荐系统。例如,一些SR模型利用LLMs直接向用户推荐项目[9]。一些SR模型则利用LLMs的输出表示来更准确地推荐个性化的项目,因为这些嵌入包含丰富的语义知识[10]。为了缓解数据稀疏和冷启动问题,一些SR模型利用LLMs生成一些数据。这些SR模型随后将生成的数据与原始数据结合,以实现更好的推荐性能。然而,LLMs也存在一些缺点。例如,基于LLMs的SR模型训练需要大量的计算资源。本综述总结了如何在SR模型中利用LLMs。在序列推荐中,建模超长交互序列变得越来越复杂。随着时间的推移,用户与越来越多的项目进行交互。随着交互序列长度的增加,训练和推理时间都会增加。同时,随着用户与越来越多的项目进行交互,交互序列中的噪音也会变得更加严重。因此,建模超长交互序列将变得越来越困难。常见的方法是从超长交互序列中提取少数已交互的项目[11]。我们的综述将总结一些常用于超长交互序列建模的方法。在我们的综述中,我们还介绍了序列推荐模型中的数据增强方法。这是因为数据增强方法可以被不同的SR模型利用。它们主要集中在生成更多的交互数据,以解决数据稀疏和冷启动问题。常见的增强方法包括对交互序列进行排序、掩蔽、裁剪等操作[12]。
本综述的贡献总结如下:
- 本综述从更全面的角度总结了关于SR模型的早期和最新研究成果。
- 本综述根据项目属性的构建将现有的SR模型分类为四类。
- 本综述总结了应用于序列推荐的最新技术。
- 本综述介绍了序列推荐模型中的实证研究和未来的研究方向。
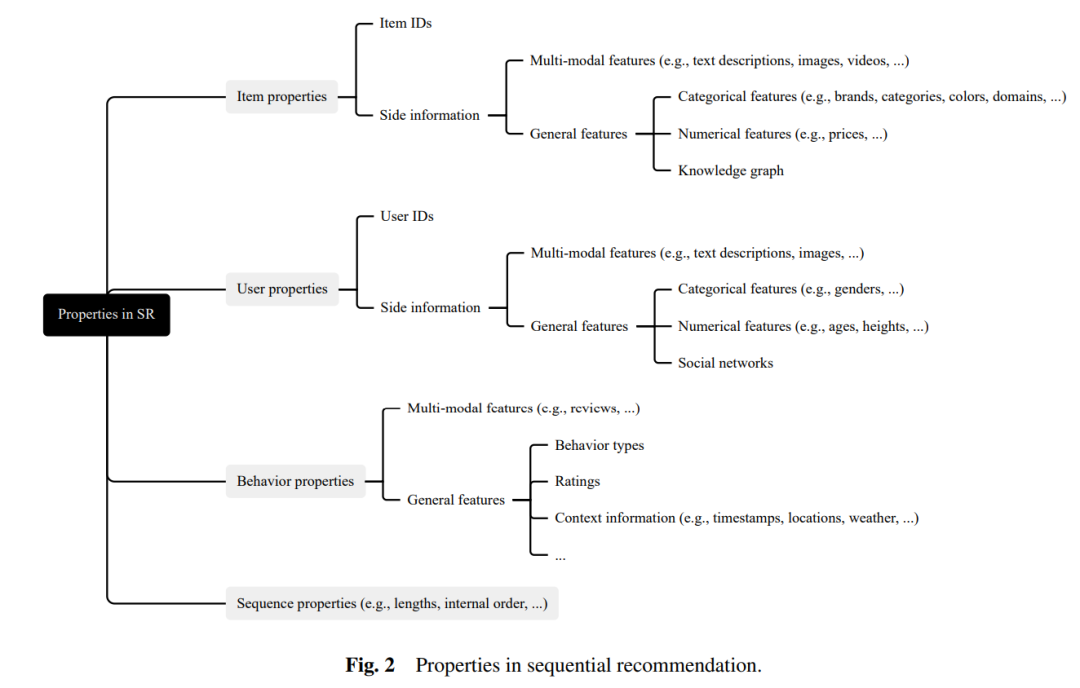
我们的综述通过一个全面的分类法介绍了序列推荐(SR)模型。如图5所示,我们的综述将从三个不同的方面介绍SR模型:(即,纯ID-based SR、带有附加信息的SR和最近的SR进展)。我们将在接下来的章节中详细讨论这些SR模型的具体细节。