

**摘要——**具身智能(Embodied AI)要求智能体具备感知、行动与预测能力,即能够预见自身行为将如何重塑未来的世界状态。**世界模型(World Models)**作为内部模拟器,用于捕捉环境动态,从而支持前向推演与反事实推演,以辅助感知、预测和决策。本综述针对具身智能中的世界模型提出了一个统一框架。具体而言,我们形式化了问题设定与学习目标,并提出了一个三轴分类体系,包括:(1)功能性维度:决策耦合型(Decision-Coupled)与通用型(General-Purpose);(2)时间建模维度:序列化的模拟与推理(Sequential Simulation and Inference)与全局差分预测(Global Difference Prediction);(3)空间表征维度:全局潜向量(Global Latent Vector)、特征标记序列(Token Feature Sequence)、空间潜在网格(Spatial Latent Grid)以及分解渲染表征(Decomposed Rendering Representation)。 我们系统化地整理了跨机器人、自主驾驶与通用视频场景的数据资源与评测指标,涵盖了像素级预测质量、状态级理解以及任务性能等方面。此外,我们对当前最先进的模型进行了定量比较,并总结出若干关键的开放挑战,包括:缺乏统一的数据集与评测基准;需要评估物理一致性而非仅关注像素保真度的指标;模型性能与实时控制所需计算效率之间的权衡;以及在长时序预测中实现时间一致性并减缓误差累积的核心建模难题。 最后,我们在以下链接维护了一个精心整理的参考文献库: https://github.com/Li-Zn-H/AwesomeWorldModels。 **关键词——**世界模型;具身智能;时间建模;空间表征。 1 引言
具身智能(Embodied AI)的目标是使智能体具备在复杂的多模态环境中进行感知(perceive)、行动(act)以及预测自身行为将如何改变未来世界状态(anticipate how actions reshape future world states)的能力 [1], [2]。支撑这一能力的核心是世界模型(world model)——一种内部模拟器(internal simulator),能够捕捉环境动态,从而通过前向推演(forward rollouts)与反事实推演(counterfactual rollouts)来支持感知、预测与决策 [3], [4]。 本综述聚焦于能够为具身智能体提供可操作性预测(actionable predictions)的世界模型,并将其与静态场景描述器(static scene descriptors)或不具备可控动态的纯生成视觉模型(purely generative visual models)区分开来。 认知科学研究表明,人类通过整合多感官输入来构建内部世界模型(internal models of the world)。这些模型不仅用于预测与模拟未来事件,还会反过来塑造感知并指导行动 [5]–[7]。受到这一观点的启发,早期人工智能领域的世界模型研究起源于基于模型的强化学习(model-based reinforcement learning, RL),其中通过隐空间状态转移模型(latent state-transition models)提升采样效率与规划性能 [8]。Ha 与 Schmidhuber 的开创性工作 [9] 首次明确提出“世界模型(World Model)”这一概念,并启发了 Dreamer 系列工作 [10]–[12],展示了通过学习环境动态来驱动基于想象的策略优化(imagination-based policy optimization)的潜力。 近期,**大规模生成建模(large-scale generative modeling)与多模态学习(multimodal learning)的进展进一步拓展了世界模型的研究边界——从最初面向策略学习的模型演化为能够进行高保真未来预测的通用环境模拟器(general-purpose environment simulators),代表性模型包括 Sora [13] 与 V-JEPA 2 [14]。这一演化过程带来了功能角色、时间建模策略与空间表征方式的多样化,同时也导致了不同子领域在术语与分类体系上的不一致。 要真实捕捉环境动态,世界模型必须同时解决状态的时间演化(temporal evolution of states)与场景的空间编码(spatial encoding of scenes)问题 [3]。在长时序(long-horizon)推演中,误差积累会显著影响模型连贯性(coherence),使其成为视频预测与策略想象中的核心挑战 [15], [16]。同样,过于粗糙或二维导向的布局(2D-centric layouts)难以捕捉遮挡、物体持久性(object permanence)与几何感知规划(geometry-aware planning)所需的几何细节。相比之下,体积或三维占据表征(volumetric or 3D occupancy representations)——如神经场(neural fields)[17] 和结构化体素网格(structured voxel grids)[18]——提供了显式的几何结构,更有利于预测与控制。 综上所述,时间建模(temporal modeling)与空间表征(spatial representation)构成了世界模型的两大核心设计维度,它们从根本上决定了模型的预测时域(predictive horizon)、物理一致性(physical fidelity)以及具身智能体的下游性能。 近年来,已有若干综述试图梳理世界模型的快速发展文献,整体上可分为两类研究路径。 第一类是功能导向(function-oriented)视角。例如,Ding 等人 [4] 基于理解与预测两项核心功能对相关工作进行了分类,而 Zhu 等人 [19] 则从世界模型的核心能力构建了框架。 第二类是应用驱动(application-driven)视角,聚焦于特定领域,如自动驾驶。Guan 等人 [20] 与 Feng 等人 [21] 分别综述了面向自动驾驶的世界模型技术。 为解决具身智能场景下缺乏统一分类体系的问题,本文提出了一个以功能性(functionality)、时间建模(temporal modeling)与空间表征(spatial representation)三大核心轴为中心的框架。在功能维度上,我们区分了决策耦合型(decision-coupled)与通用型(general-purpose)模型;在时间维度上,区分了序列化模拟与推理(Sequential Simulation and Inference)与全局差分预测(Global Difference Prediction);在空间维度上,涵盖了从潜特征表征(latent features)到显式几何结构(explicit geometry)与神经场(neural fields)**的多种表征形式。 该框架为现有方法提供了统一的组织结构,并整合了标准化的数据集与评测指标,从而便于量化比较,并为后续研究提供了全景化的知识图谱与可操作的研究路线。
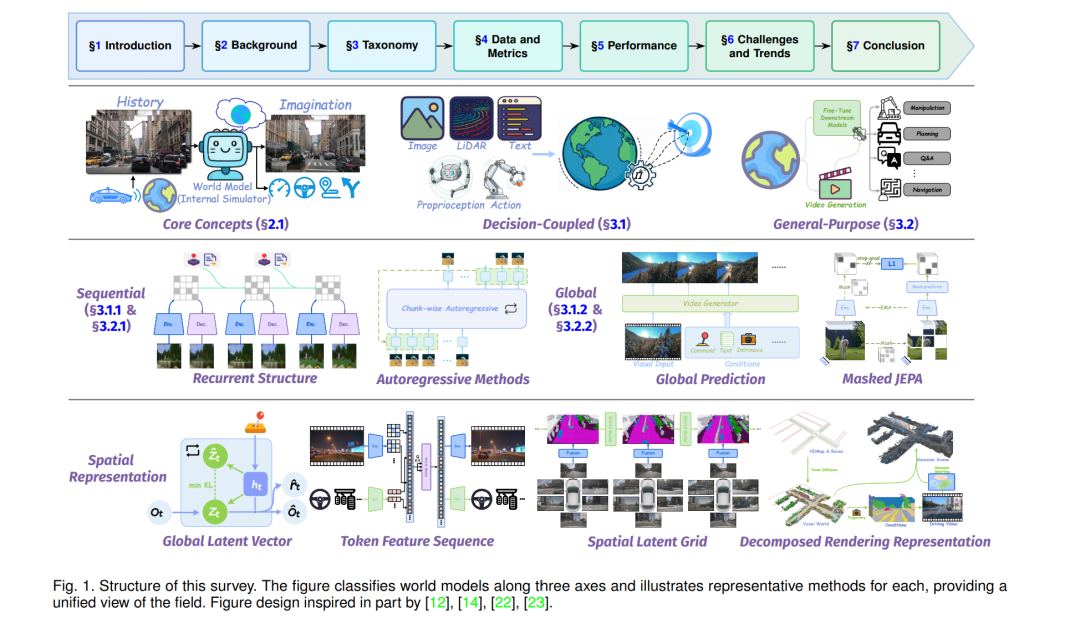
图 1 展示了本文的整体结构与分类体系。第 2 节概述世界模型的核心概念与理论基础;第 3 节介绍我们提出的三轴分类体系,并将代表性方法映射到该框架中;第 4 节梳理训练与评估中使用的数据集和指标;第 5 节给出当前最先进模型的定量比较;第 6 节讨论开放挑战与潜在研究方向;第 7 节对全文进行总结。
