

在我的博士研究期间,大型语言模型(LLMs)从一个相对新兴的研究方向发展成为现代计算机科学中最热门的领域之一。迄今为止,这些模型仍在以快速的步伐不断进步,各种行业团体争相将其投入生产,应用于多个业务领域。然而,这一进展并非全然正面——我们已经观察到,AI模型的部署已导致广泛的安全、隐私和稳健性失败。 在本论文中,我将讨论构建值得信赖和安全的LLMs的理论与实践。在第一部分,我将展示LLMs如何在训练过程中记忆文本和图像,这使得对手能够从模型的训练集提取私密或受版权保护的数据。我将提出通过数据去重和差分隐私等技术来缓解这些攻击,展示攻击有效性降低几个数量级的结果。 在第二部分,我将展示在部署过程中,对手可以发送恶意输入来触发错误分类或启用模型滥用。这些攻击可以是普遍性和隐蔽性的,我将展示它们需要对抗训练和系统级防护措施的新进展来进行缓解。 最后,在第三部分,我将展示在语言模型部署后,对手可以通过污染反馈数据(提供给模型开发者的反馈数据)来操控模型的行为。我将讨论如何通过新的学习算法和数据过滤技术来缓解这些风险。


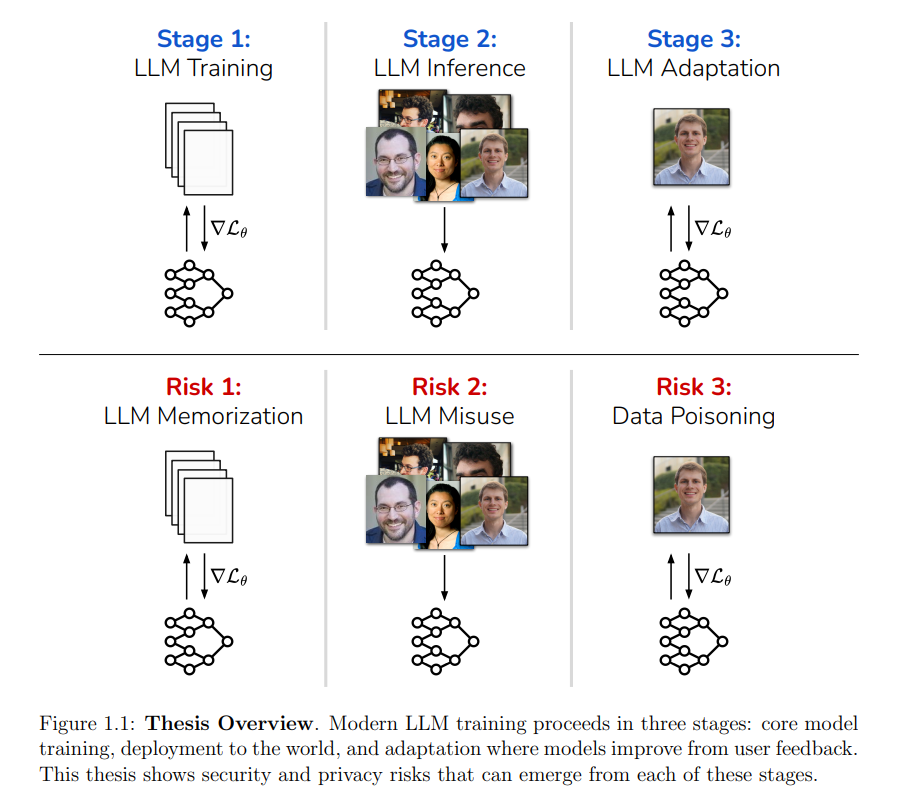
尽管取得了这些成功,但在本论文中,我将展示现代AI系统也存在广泛的安全性和隐私漏洞。例如,医疗助手可能被迫泄露用户的私人数据,写作助手可能会无意中复制受版权保护的文本段落,而对手可以滥用电子邮件写作工具来制作更有效的钓鱼攻击。这些脆弱性不仅仅是理论上的:其中许多已经在现实世界的部署中得到了验证。 我将深入分析这些脆弱性,通过一系列已发布的工作,展示这些攻击在现实世界的LLM系统中的首次识别与度量。在此过程中,我将提出能够通过修改模型的训练集、算法或模型架构来缓解这些脆弱性的防御技术。 本论文的结构遵循构建和部署现代LLM的生命周期: 1. 第一部分:预训练阶段
现代LLM在大量语料库上进行训练。本部分展示了模型在此阶段可能无意中记住文本,导致用户隐私、版权侵犯和数据所有权等方面的严重问题。我将提出数据去重、差分隐私和基于强化学习的人类反馈(RLHF)等技术,来缓解这些风险。 1. 第二部分:部署阶段
模型训练完成后,部署到实际应用中。本部分将介绍一个通用框架,用于创建能够操控模型预测的对抗性输入。这包括经典威胁(例如,避开垃圾邮件过滤器)和新兴问题(例如,劫持LLM代理或绕过内容保护措施)。 1. 第三部分:迭代与持续学习
模型部署后,组织会收集反馈数据并对模型进行迭代。本部分探讨了现实世界系统如何在此过程中演变,并展示了对手如何通过“污染”模型训练集,系统地影响部署模型的未来版本。我将提出基于数据过滤、差分隐私和学习算法修改的缓解措施。
